【取证】2026 FIC全国网络空间取证大赛预选赛WriteUp(计算机部分)

【取证】2026 FIC全国网络空间取证大赛预选赛WriteUp(计算机部分)
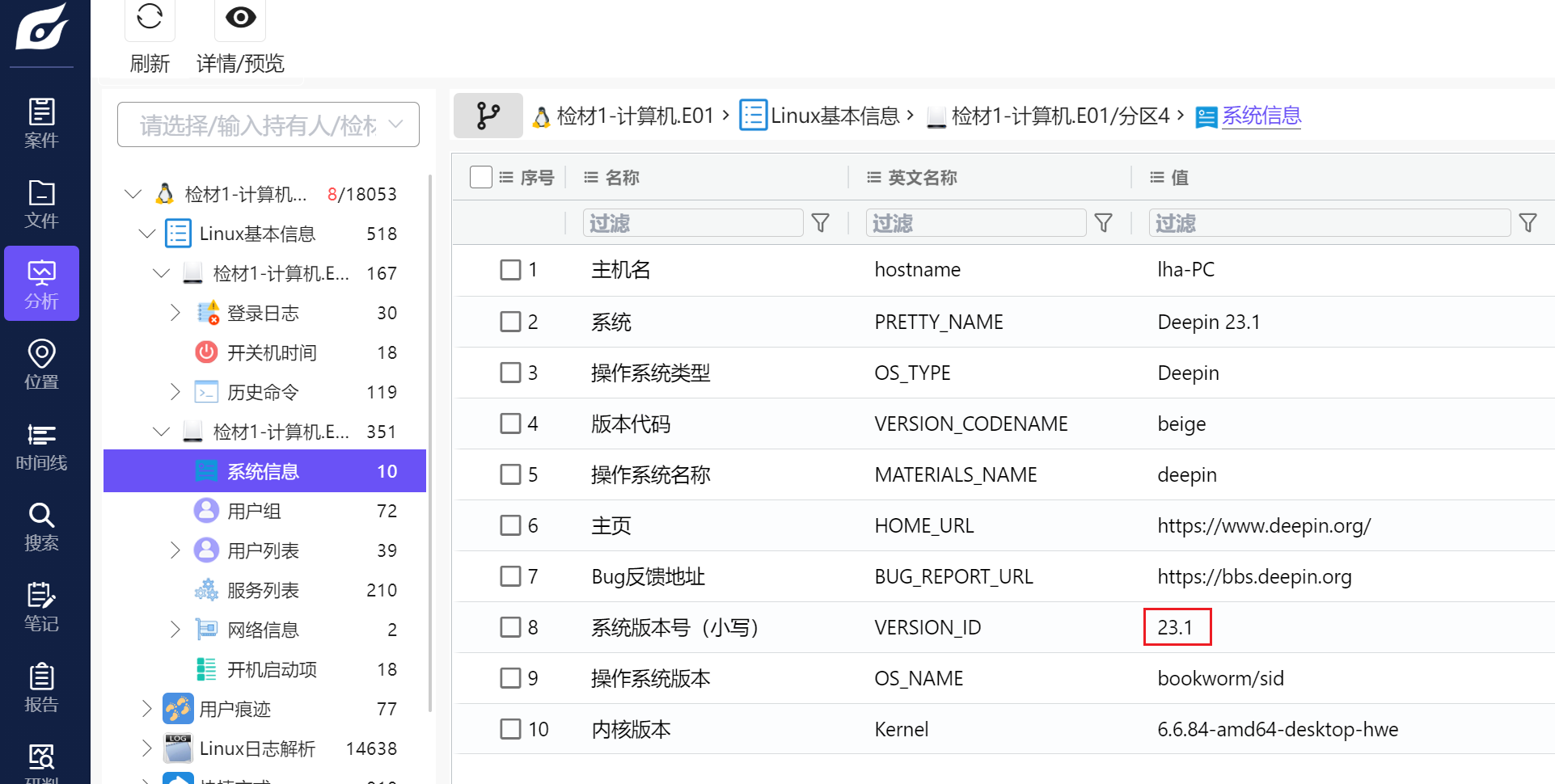
FatPig1. 分析计算机检材,操作系统版本号为
9.00 分
【不区分大小写】【不区分空格】【不区分换行符 (不考虑末尾)】【不区分全半角】
【参考格式:1.1】
23.1
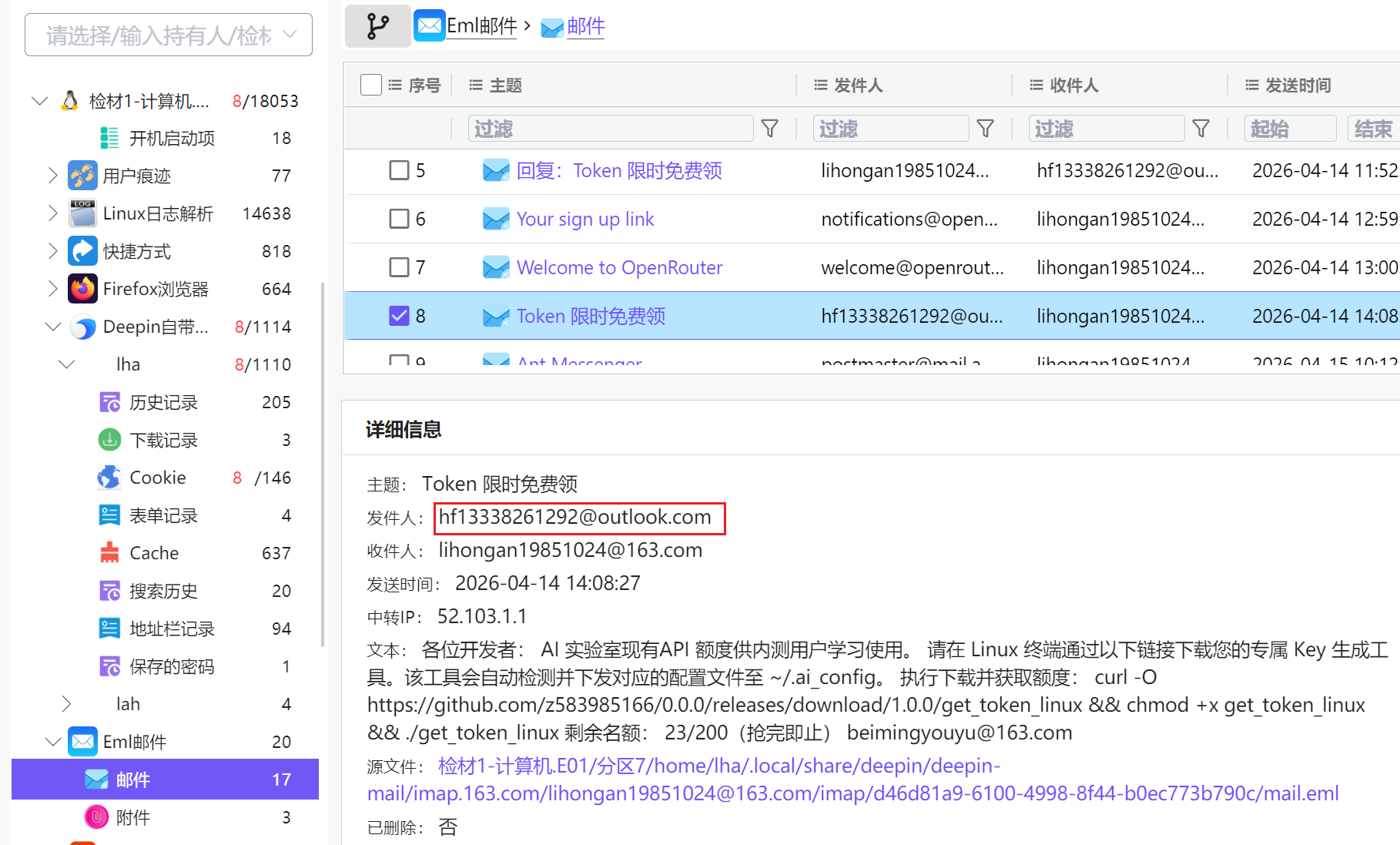
2. 分析计算机检材,李安弘曾收到一份免费领取token的邮件的疑似钓鱼邮件,其发送用户邮箱为
10.00 分
【不区分大小写】【不区分空格】【不区分换行符 (不考虑末尾)】【不区分全半角】
【参考格式:123@qq.com】
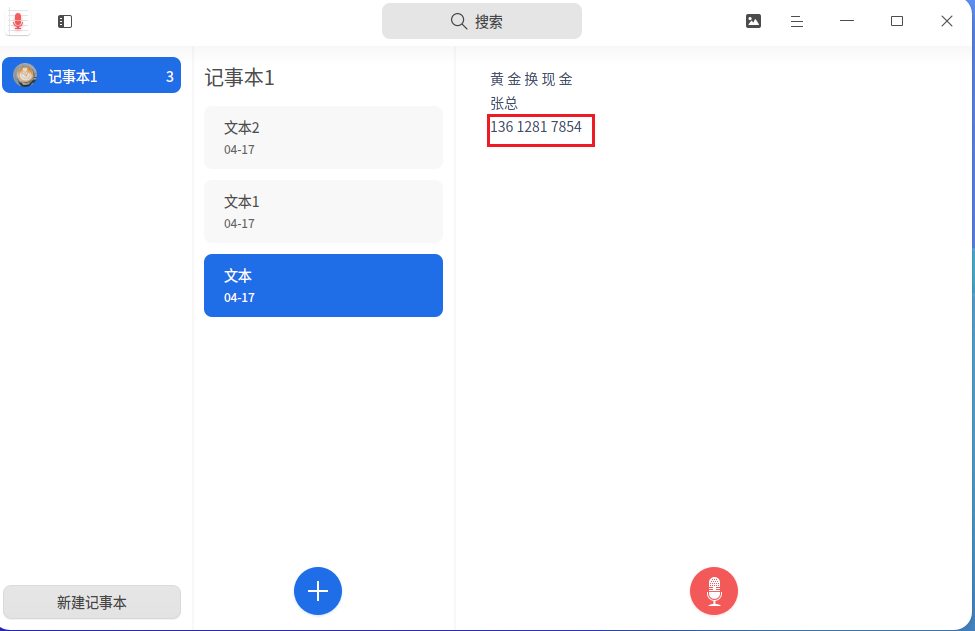
3. 分析计算机检材,李安弘电脑中记录的黄金换现金的商家联系方式为
11.00 分
【不区分大小写】【不区分空格】【不区分换行符 (不考虑末尾)】【不区分全半角】
【参考格式:110】
13612817854
仿真后在语音记事本中可以找到相关笔记记录
4. 分析计算机检材,推广设计图中的apk下载链接为
13.00 分
【不区分大小写】【不区分空格】【不区分换行符 (不考虑末尾)】【不区分全半角】
【参考格式:http:///?*】
https://drive.google.com/file/d/1z3aRS-lkaJYKm7Cp1XjtUmVPsOEVW2fV/view?usp=sharing
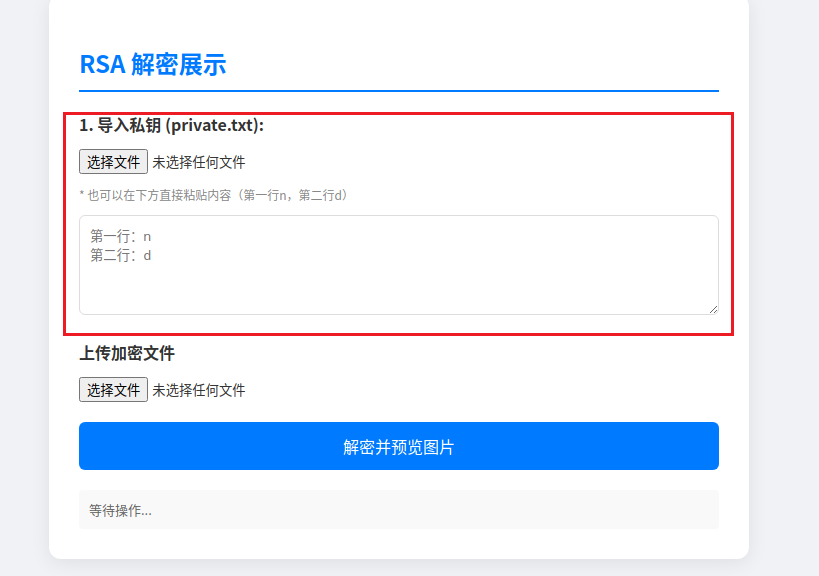
在邮件和用户lha的下载目录中发现加密的’’推广设计图.png.enc’’,同时还有解密用的加密图片查看.html,以及公钥public.txt,用浏览器打开加密图片查看.html,发现解密需要私钥private.txt(第一行n,第二行d),查看public.txt,发现不是常见的—–BEGIN PUBLIC KEY—–开头的PEM证书格式,而是两行数字,结合前面加密图片查看.html显示的私钥格式是第一行n,第二行d,可以判定本题使用的是RSA密钥采用的原始十进制数字格式,题目需要我们尝试计算出私钥进行解密。
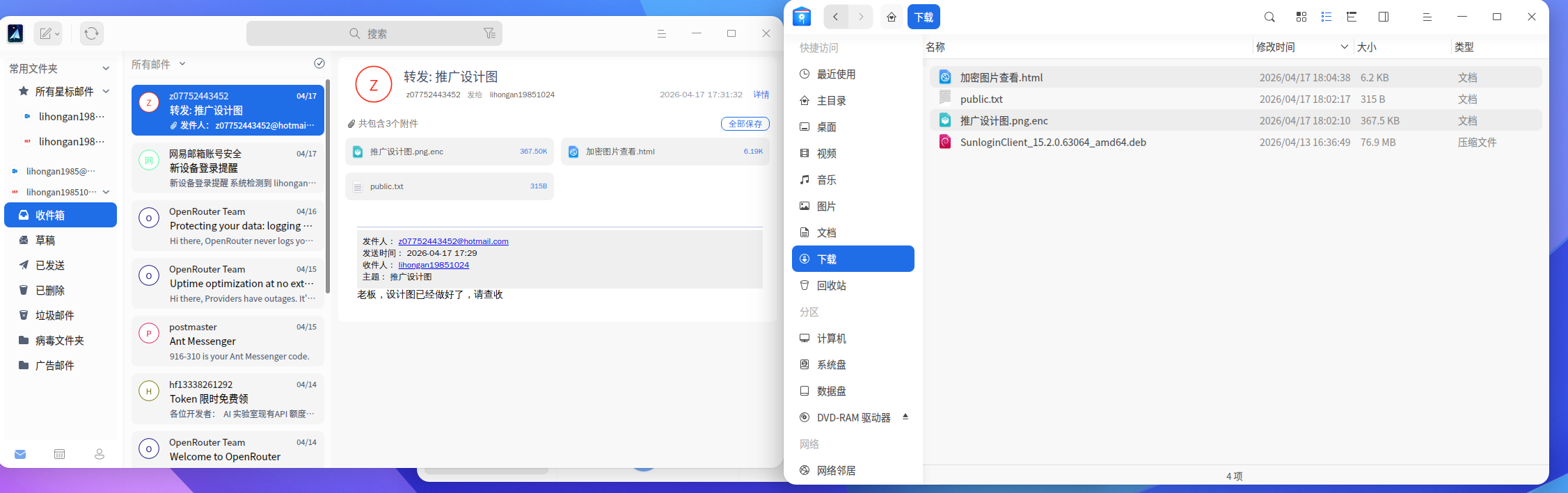

RSA中加解密过程中涉及几个主要参数n(模数)、e(公钥指数)、d(私钥指数)、p、q(质因数),
推荐看一下B站视频补充一下RSA算法基础知识
https://www.bilibili.com/video/BV1XP4y1A7Ui
https://www.bilibili.com/video/BV14y4y1272w
https://www.bilibili.com/video/BV1YQ4y1a7n1
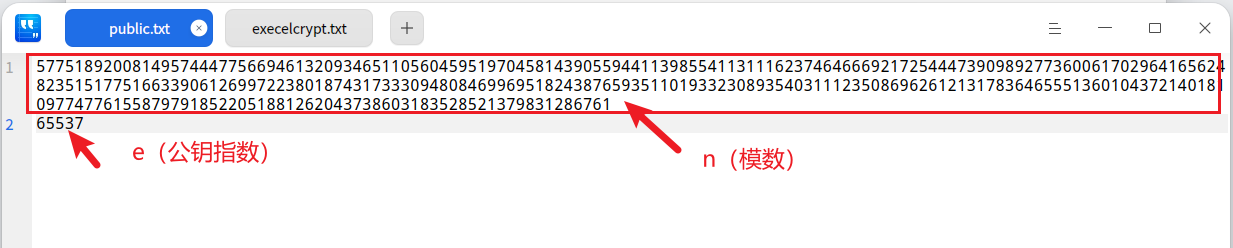
学习完基础知识,我们现在可以看懂了public.txt中的第一行是n(模数)、第二行是e(公钥指数),我们要根据这两个信息计算出p、q(质因数),进而计算出d(私钥指数)就可以进行解密’’推广设计图.png.enc’’。
方法一:在线工具 dcode.fr
首先使用这个网站的Prime Factors Decomposition(https://www.dcode.fr/prime-factors-decomposition)工具对模数n(public.txt中的第一行)进行质因数分解,得到p、q的值
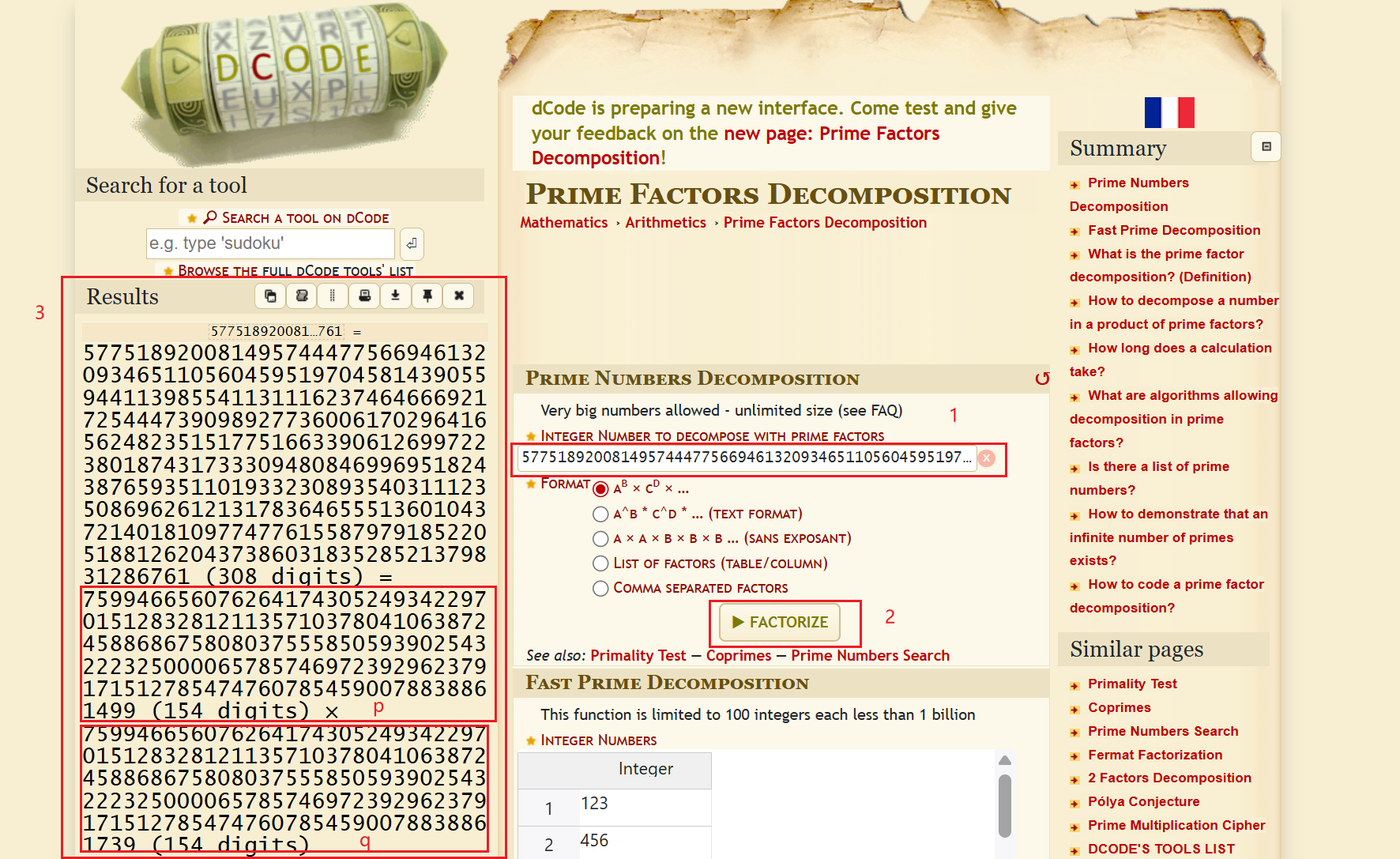
然后这个网站的RSA Cipher(https://www.dcode.fr/rsa-cipher)功能计算出私钥中的d的数值
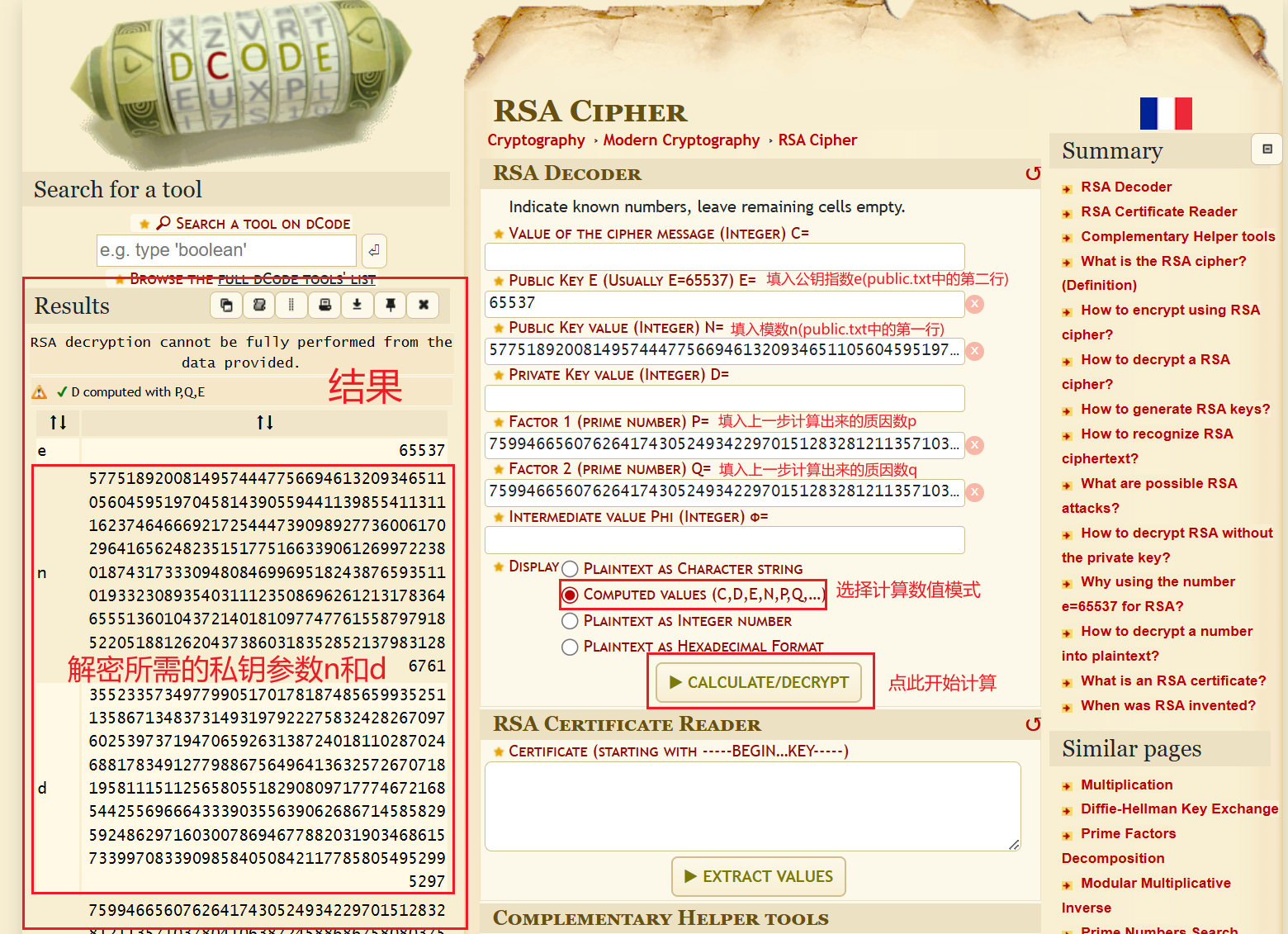
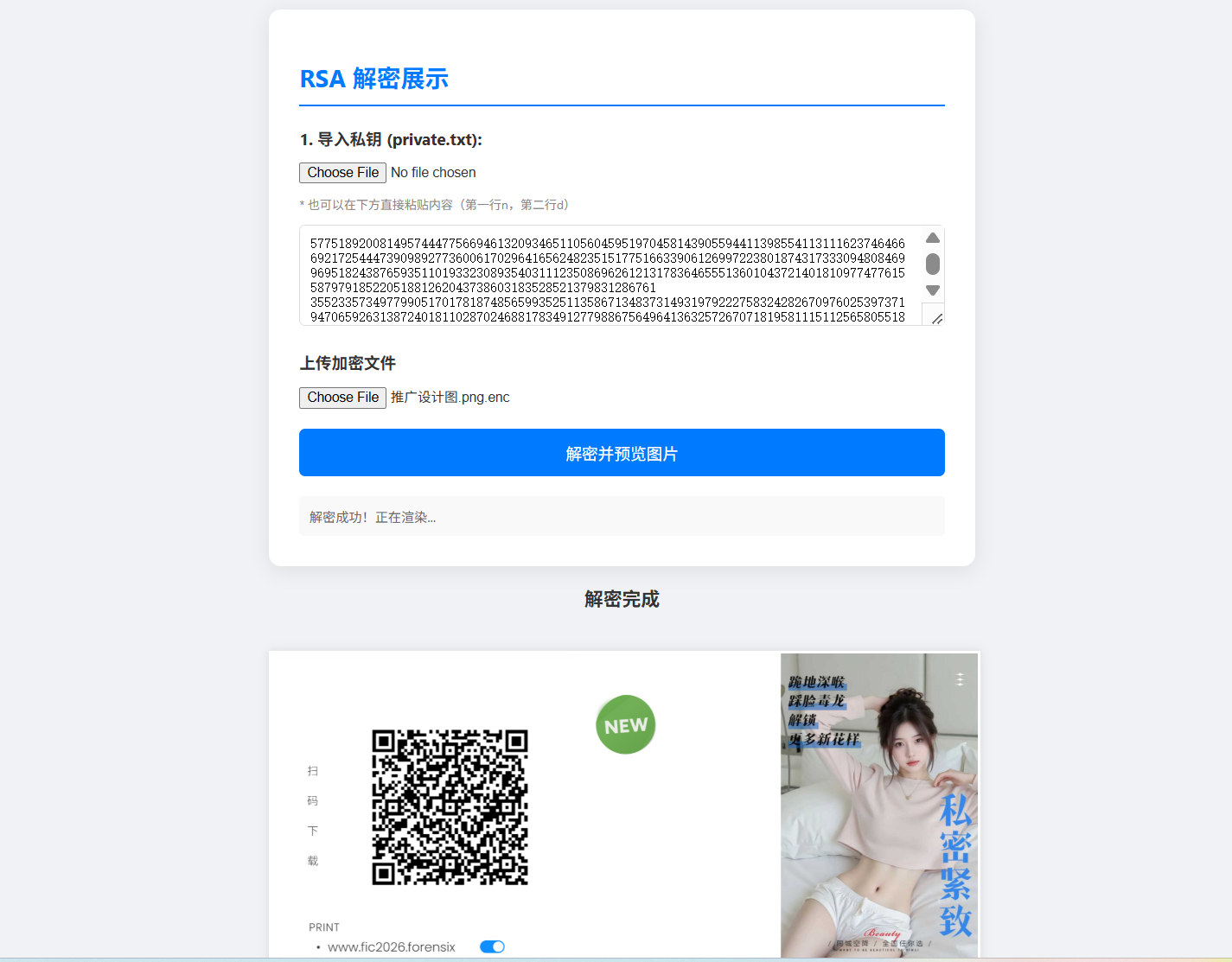
使用题目提供的加密图片查看.html进行解密,帮上一步得到的n粘贴到第一行,d粘贴到第二行就可以进行解密了,识别解密后的图片二维码即可得到答案https://drive.google.com/file/d/1z3aRS-lkaJYKm7Cp1XjtUmVPsOEVW2fV/view?usp=sharing
方法二、离线工具RsaCtfTool+ASN.1 JavaScript decoder
RsaCtfTool下载地址(https://github.com/RsaCtfTool/RsaCtfTool)
ASN.1 JavaScript decoder下载地址(https://asn1js.eu/asn1js.zip)在线使用地址(https://asn1js.eu/)
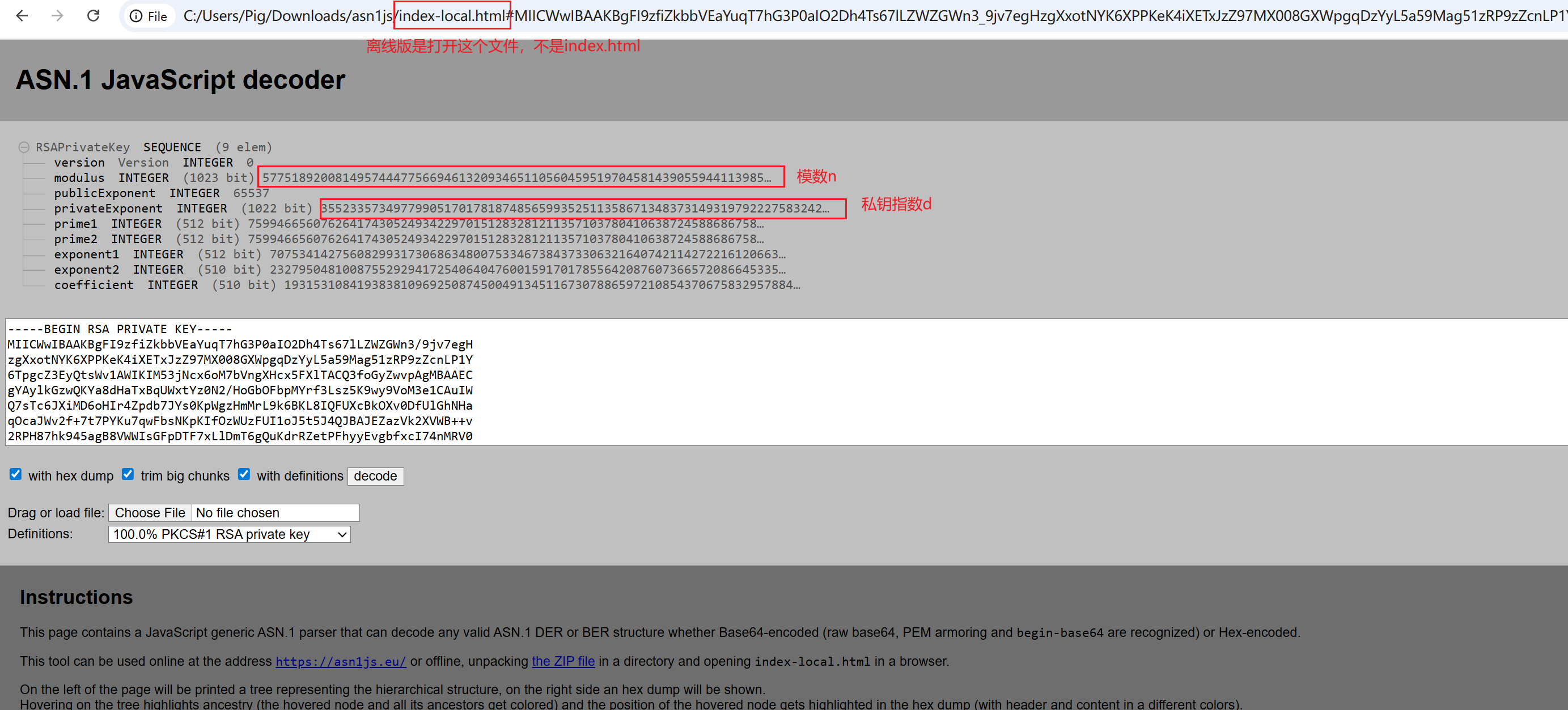
RsaCtfTool用于计算出私钥,ASN.1 JavaScript decoder用于将RsaCtfTool计算出的pem格式的私钥转化为我们需要的n(模数)、d(私钥指数)
安装完RsaCtfTool后,使用以下命令,将public.txt中的数字参数转化为pem格式的证书
1 | RsaCtfTool --createpub -n 57751892008149574447756694613209346511056045951970458143905594411398554113111623746466692172544473909892773600617029641656248235151775166339061269972238018743173330948084699695182438765935110193323089354031112350869626121317836465551360104372140181097747761558797918522051881262043738603183528521379831286761 -e 65537 |

使用以下命令
1 | RsaCtfTool --publickey key.pub --private --attack fermat |
可以直接计算出私钥,将解密出来的私钥复制出来
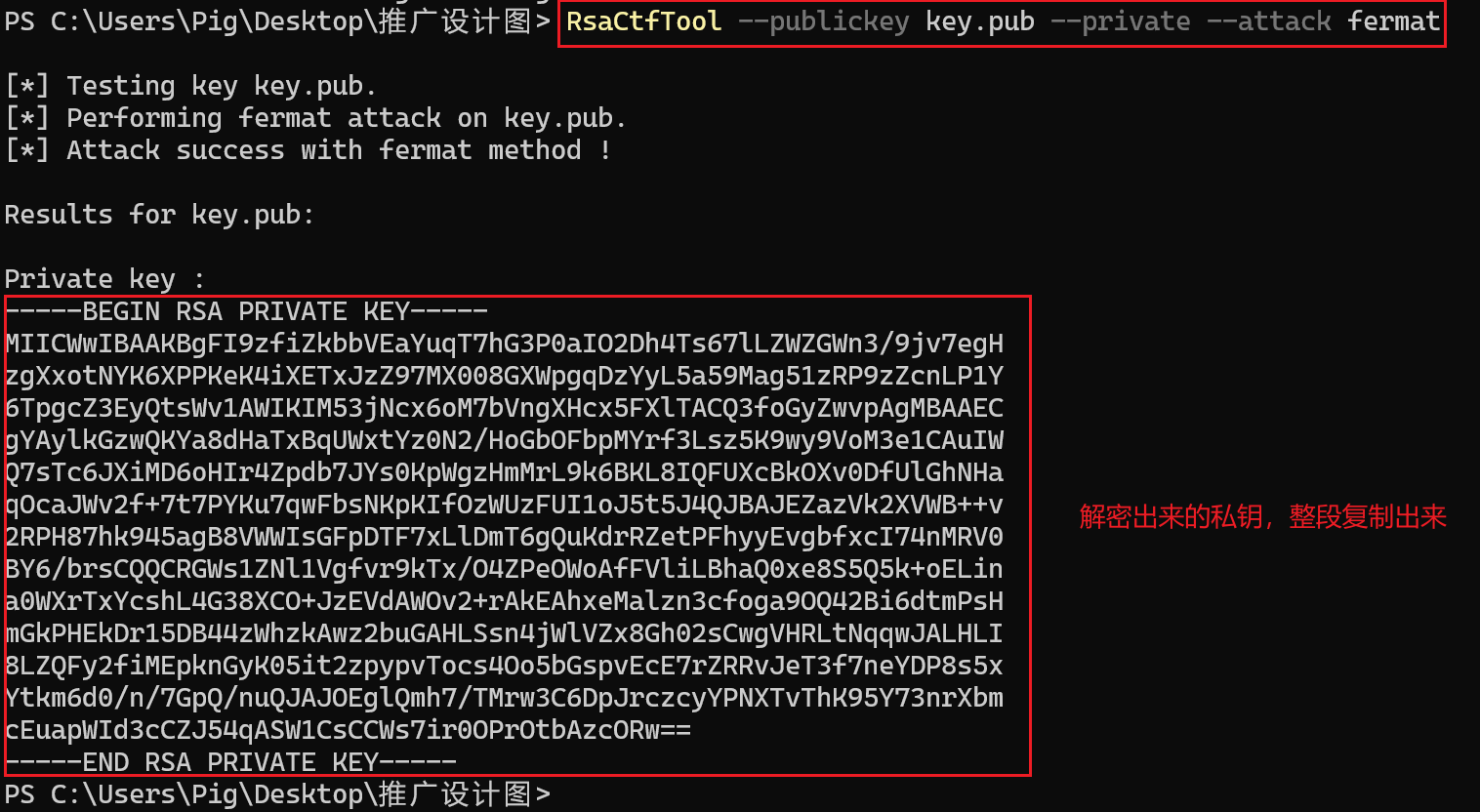
使用ASN.1 JavaScript decoder解析私钥内容,得到模数n和私钥指数d,后面的步骤同方法2一样到加密图片查看.html中进行图片解密就不再赘述。
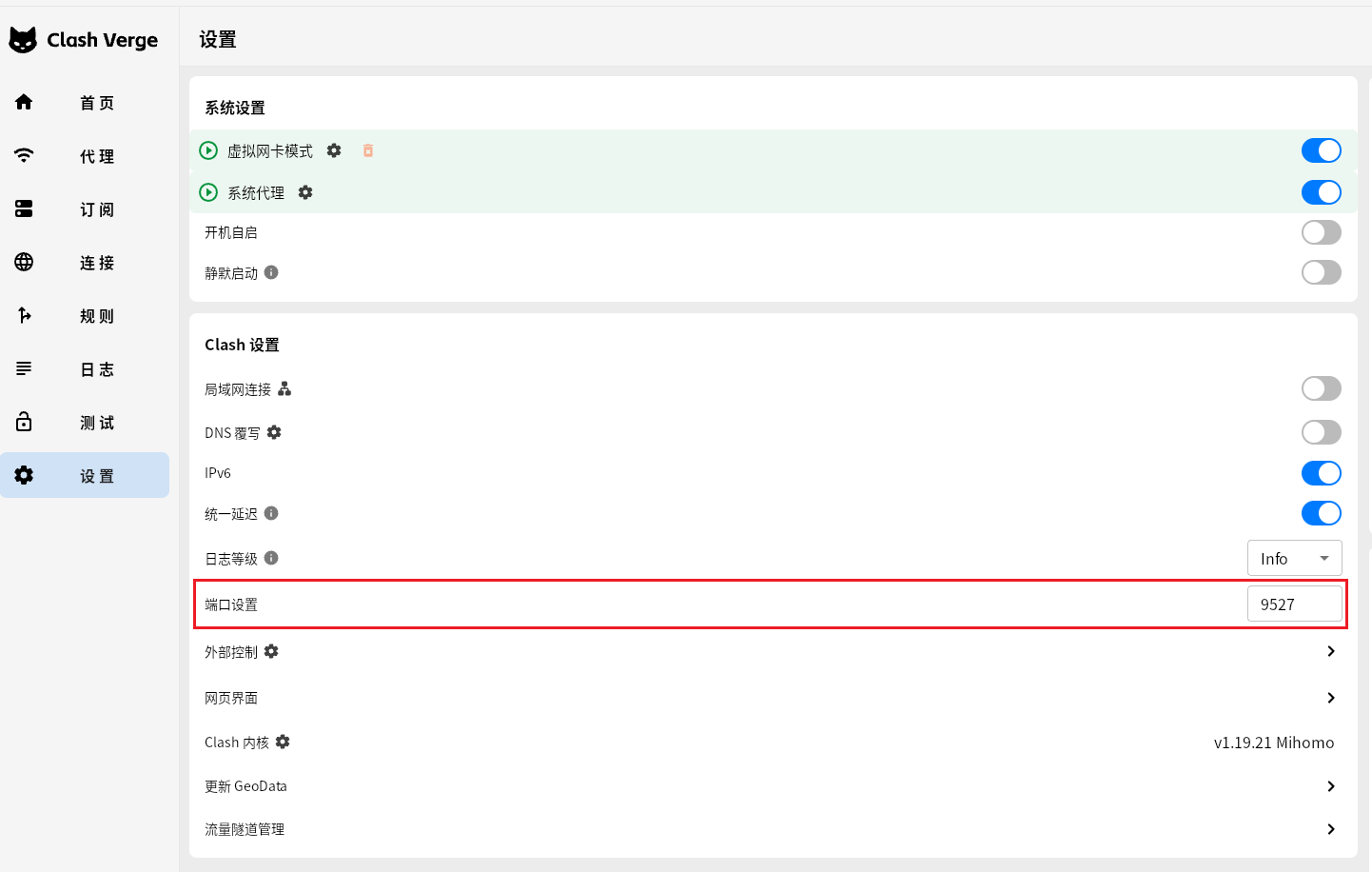
5. 分析计算机检材,李安弘电脑vpn软件开放的代理端口为
10.00 分
【不区分大小写】【不区分空格】【不区分换行符 (不考虑末尾)】【不区分全半角】
【参考格式:80】
9527
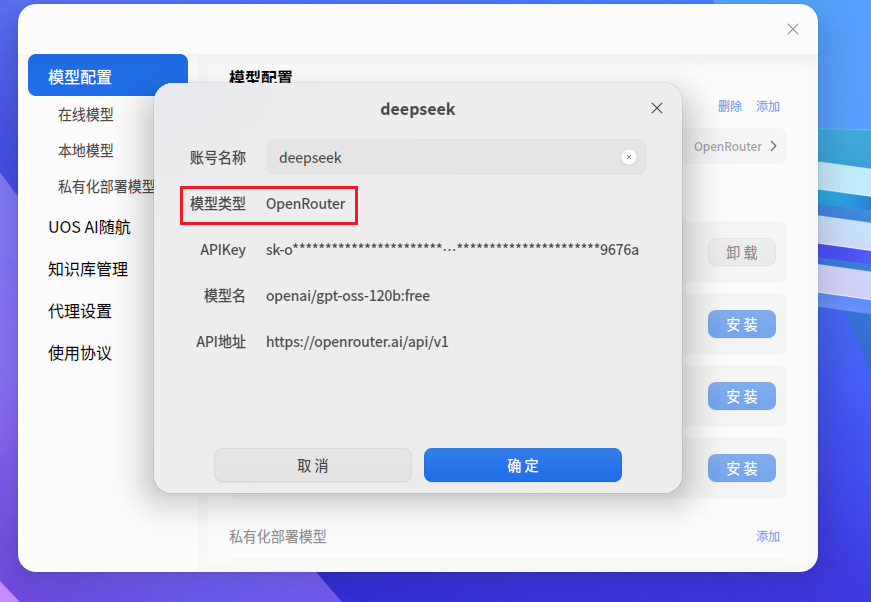
6. 分析计算机检材,李安弘电脑中AI软件当前使用的模型类型为
11.00 分
【不区分大小写】【不区分空格】【不区分换行符 (不考虑末尾)】【不区分全半角】
【参考格式:deepseek】
OpenRouter

7. 分析计算机检材,李安弘电脑中AI软件当前使用的模型apiKey为
12.00 分
【不区分大小写】【不区分空格】【不区分换行符 (不考虑末尾)】【不区分全半角】
【参考格式:sk-abcd…】
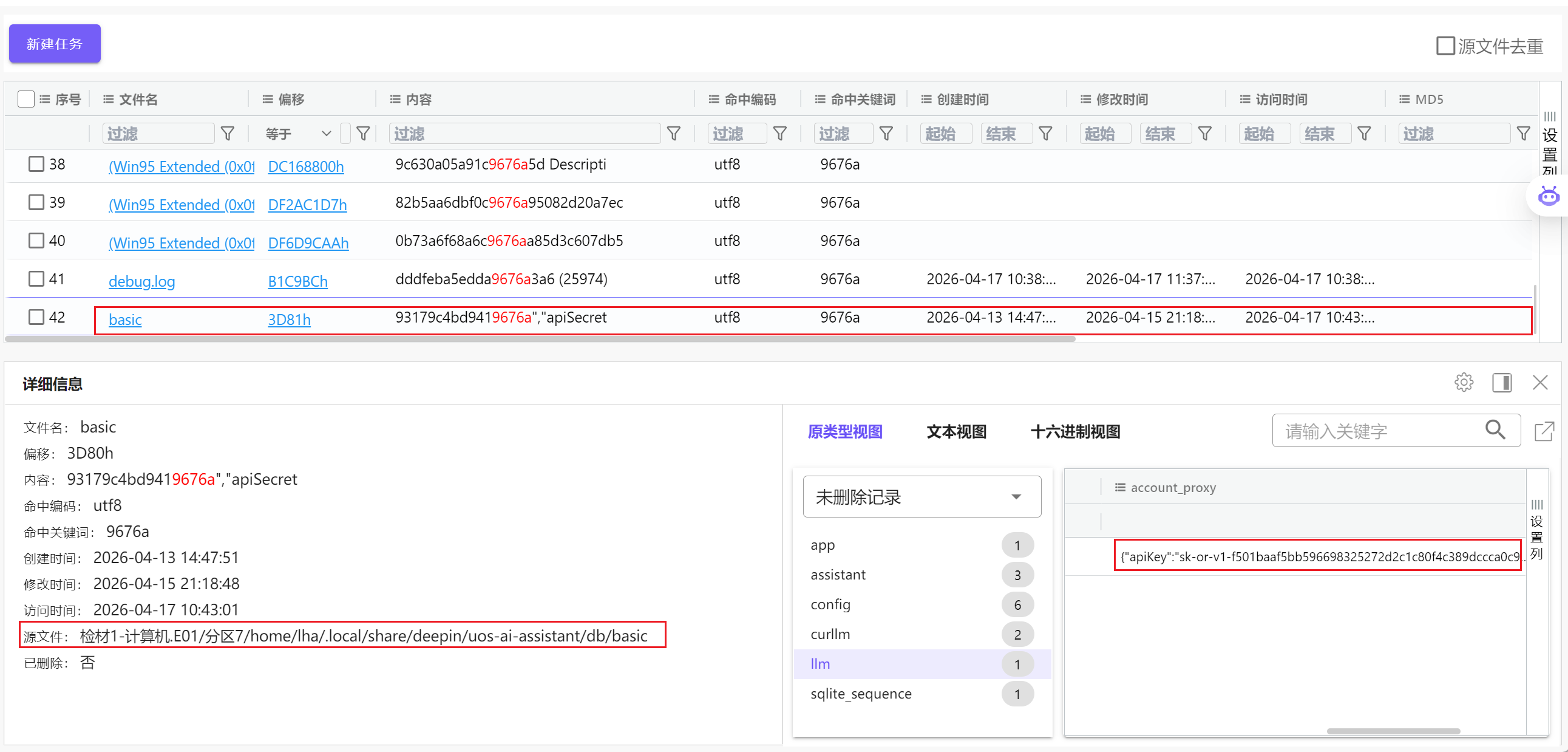
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
根据上题得到的apikey的尾数9676a作为关键字进行全文检索,快速定位到存储apikey的数据库文件/home/lha/.local/share/deepin/uos-ai-assistant/db/basic,在llm表中找到完整的apikey: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
8. 分析计算机检材,李安弘电脑中勒索软件提供的解密服务联系方式为
11.00 分
【不区分大小写】【不区分空格】【不区分换行符 (不考虑末尾)】【不区分全半角】
【参考格式:abcd123232】
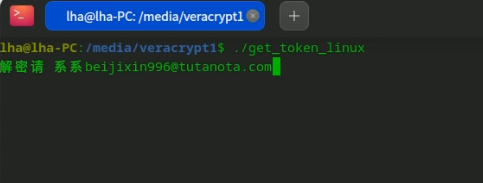
根据第二题的提示,李安弘曾收到一份钓鱼邮件,根据邮件中的内容可以知道可疑恶意程序文件名为get_token_linux,使用火眼索引搜索get_token_linux,没有搜索到相关文件,只相关终端历史命令。
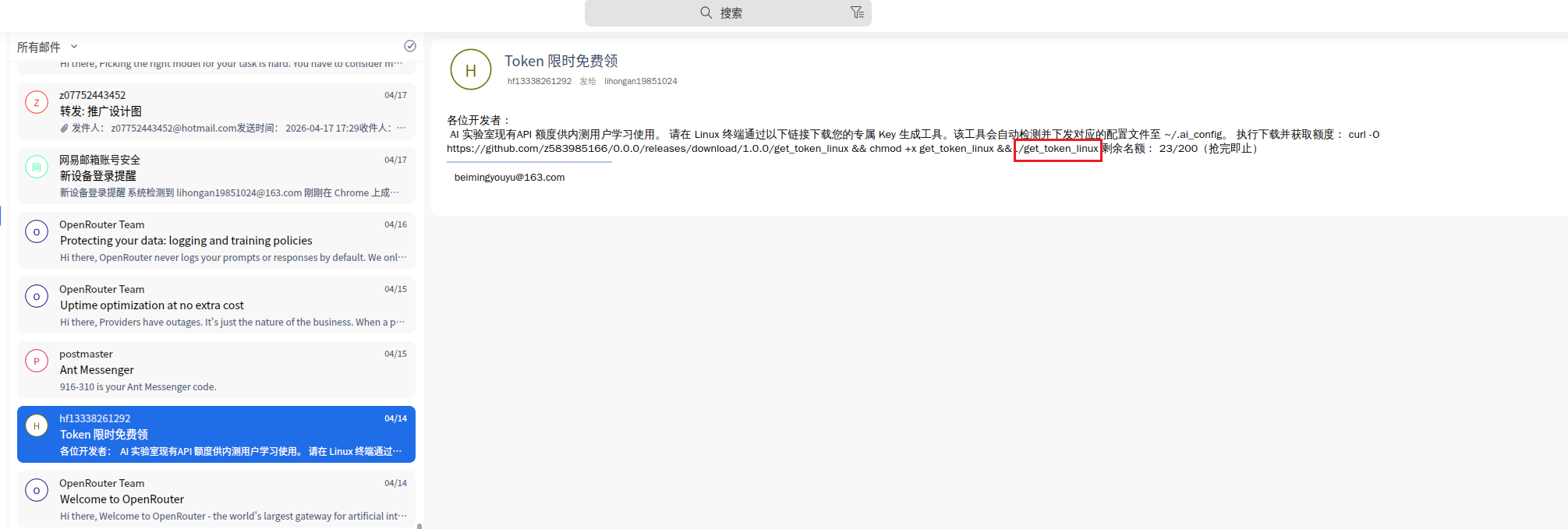
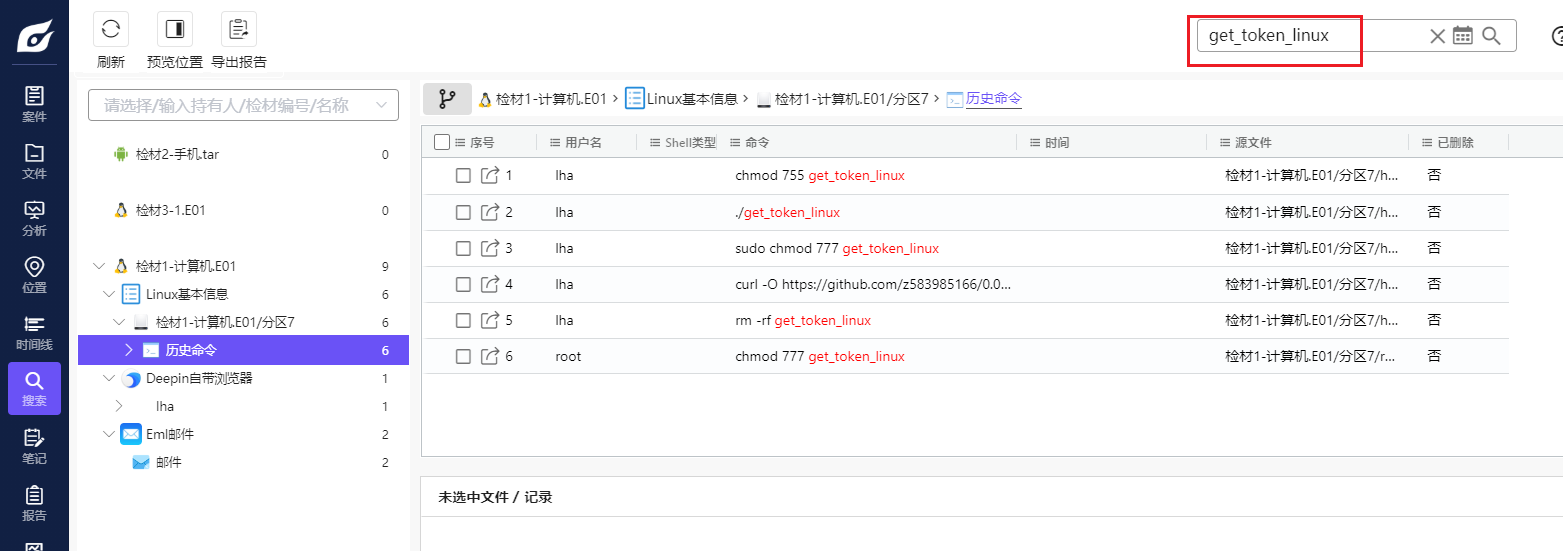
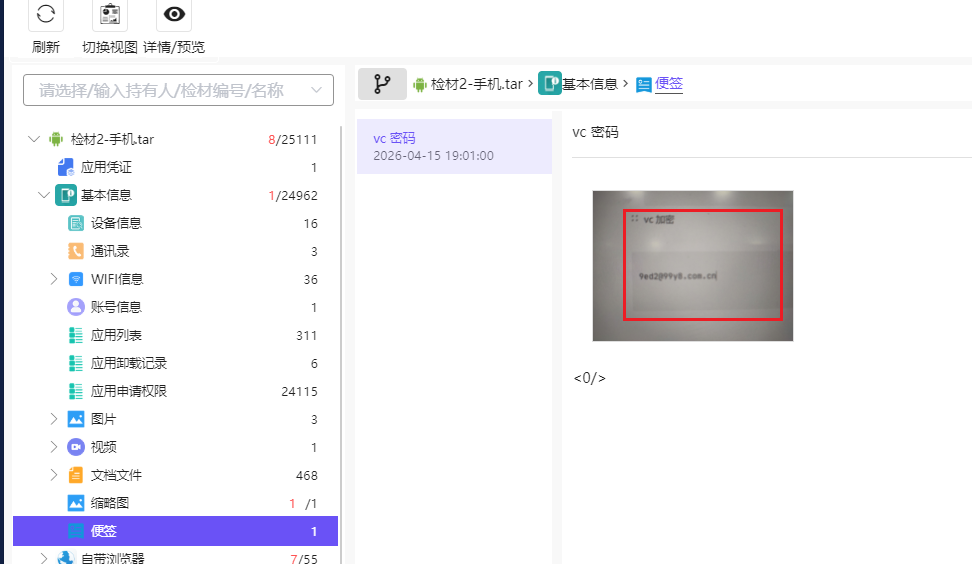
加载镜像时,火眼有提示分区3是vc加密卷,考虑有与题目相关重要文件藏在里面,在手机检材的便签中可以找到vc密码9ed2@99y8.com.cn,尝试用这个密码解密分区3,成功解密,并且我们在该分区中找到了我们要找的恶意程序get_token_linux
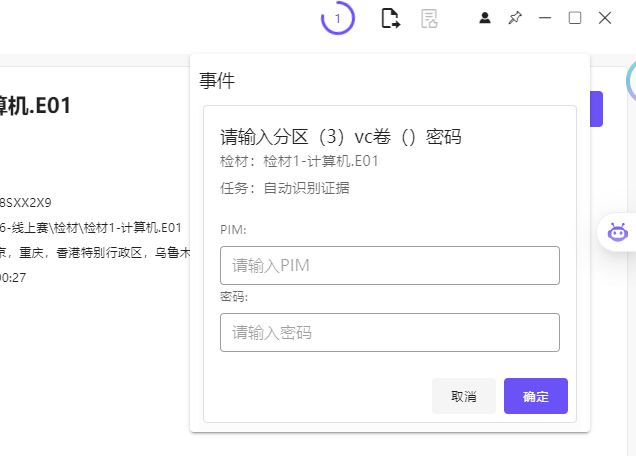
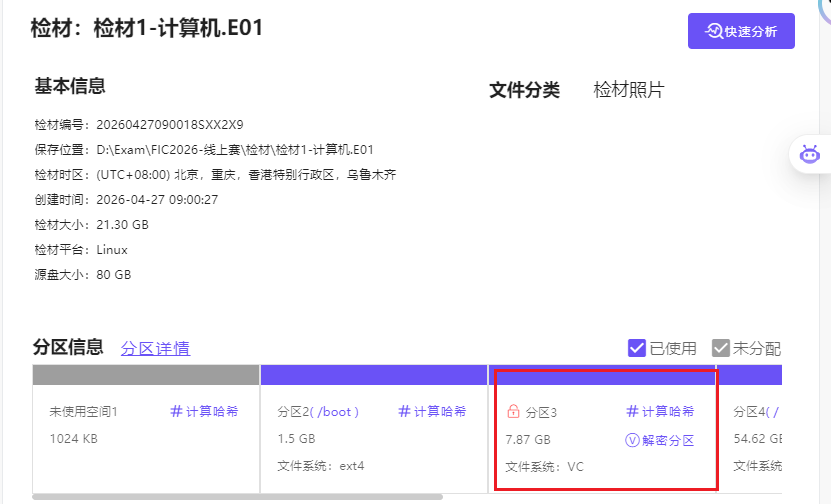
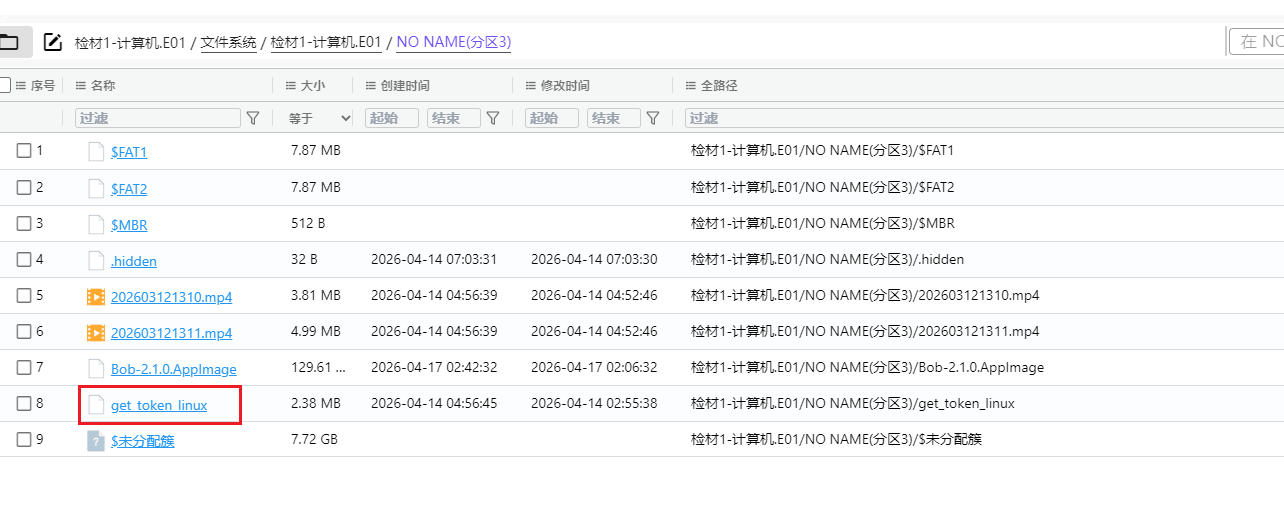
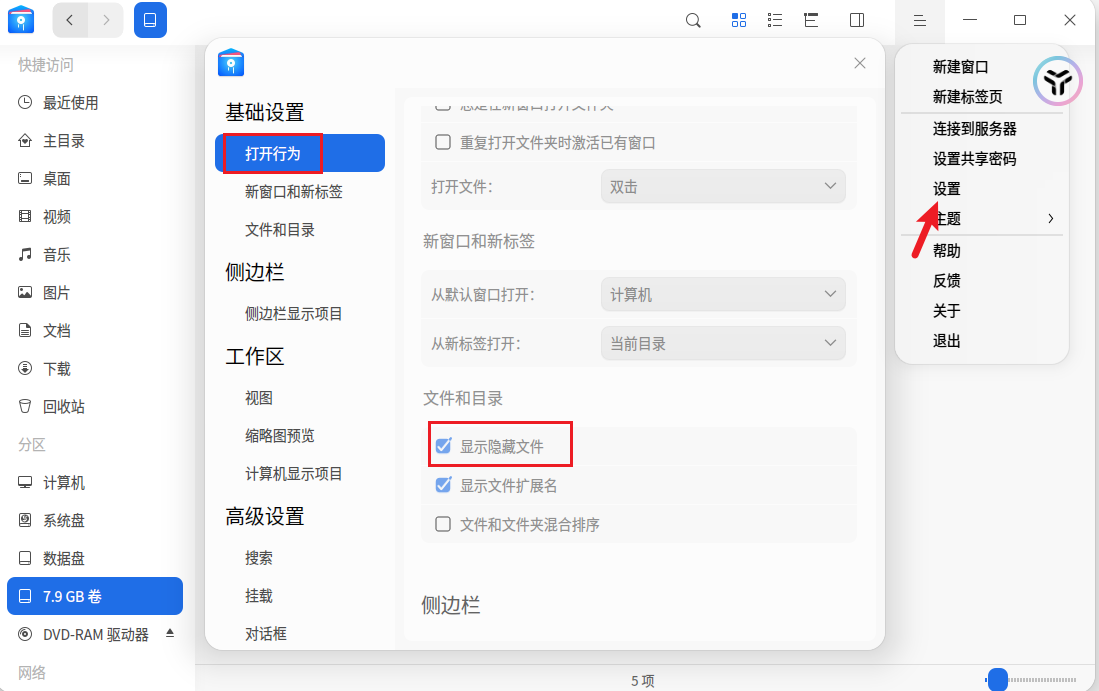
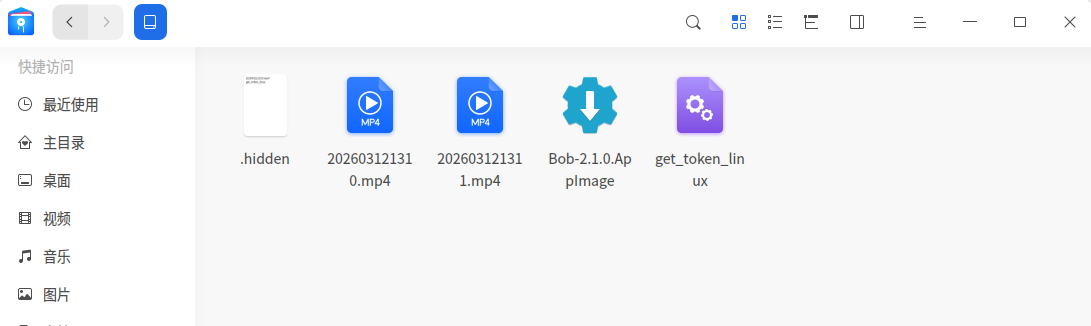
我们回到仿真镜像中,尝试将这个加密分区解密并挂载然后去执行一下get_token_linux看看,首先我们在lha的用户目录下的tool目录找到了VeraCrypt的应用程序VeraCrypt-1.26.24-x86_64.AppImage,双击打开,select device,选择/dev/sda2进行解密挂载,为了让挂载后能够执行程序,我们需要在文件管理器的设置打开显示隐藏文件的选项后,即可看到全部文件,包括我们要找到的get_token_linux
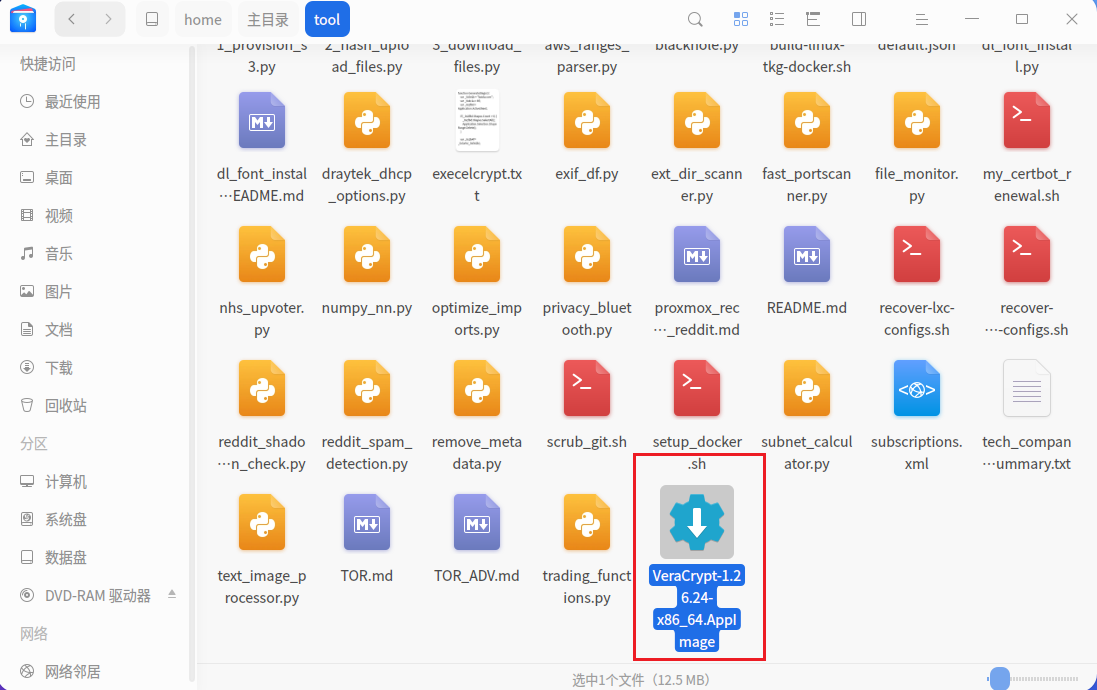
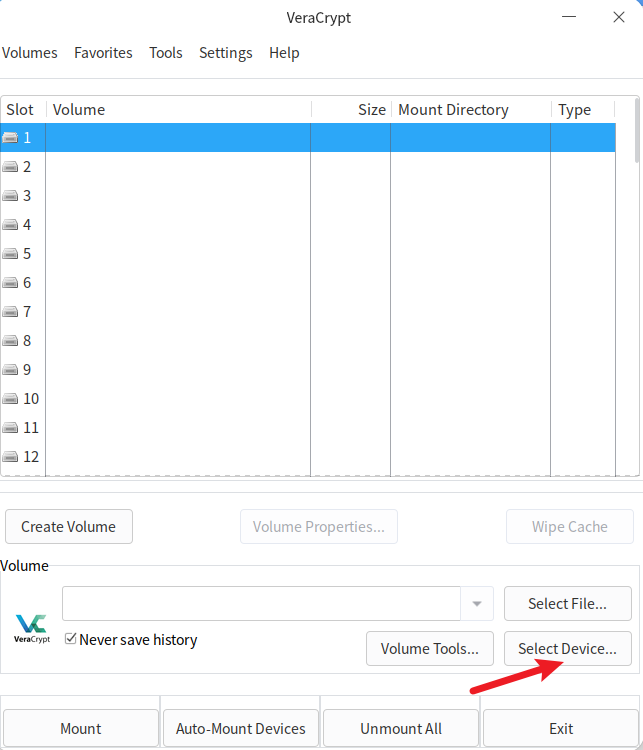
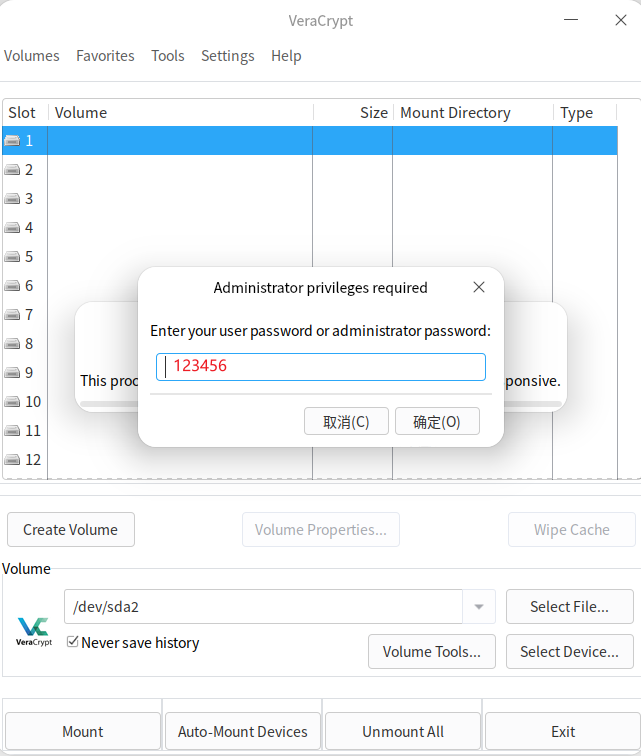
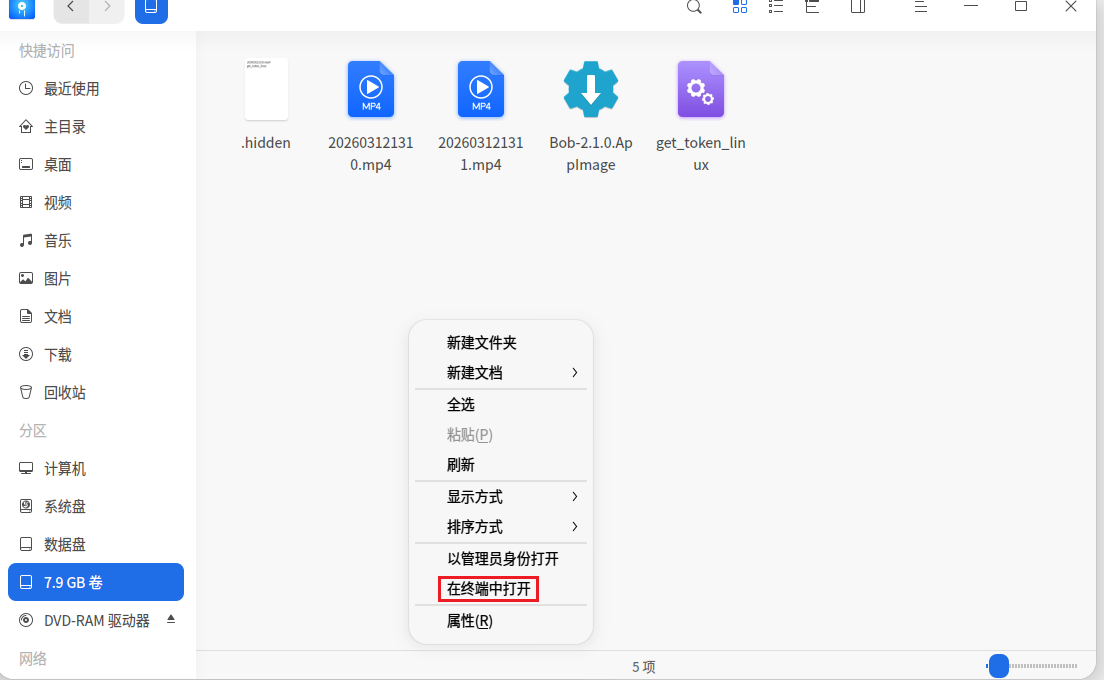
点击右键在终端中打开,并执行以下命令运行get_token_linux,可以看到 解密请 系系beijixin996@tutanota.com 的内容
9. 分析计算机检材,李安弘电脑中记录的存放黄金的保险柜编号是
13.00 分
【不区分大小写】【不区分空格】【不区分换行符 (不考虑末尾)】【不区分全半角】
【参考格式:1】
997546
加密分区内除了get_token_linux还有两个视频文件,尝试播放发现只有声音没有视频画面,其中202603121310.mp4的声音听的像开关铁柜门的声音,而且还有滴的一声,初步判断本题的答案黄金的保险柜编号可能藏在视频画面中,视频可能被get_token_linux加密了
使用IDA Pro逆向分析get_token_linux,寻找加密逻辑,查看main.main 函数和main._a 函数 (0x4ad440)可以知道该程序的加密逻辑
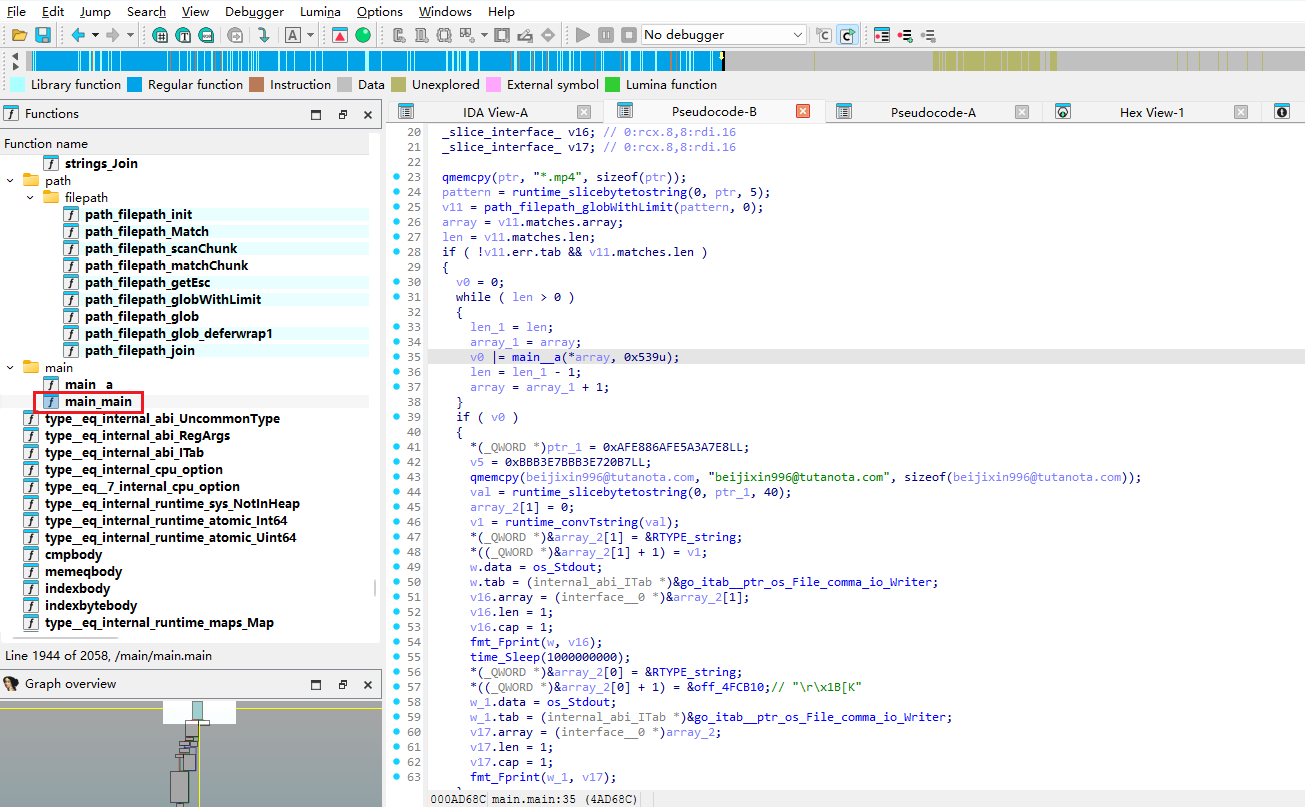
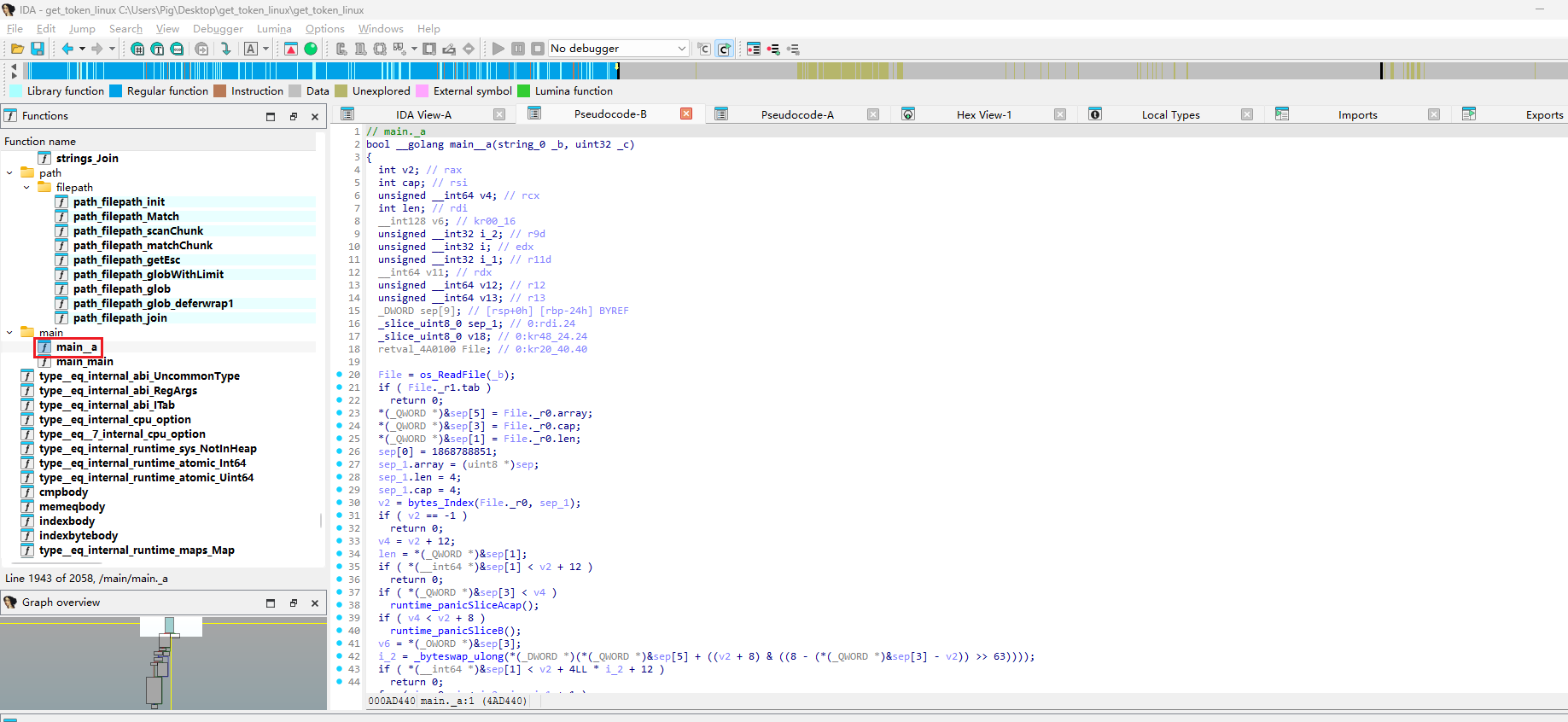
核心加密逻辑分析
main.main 函数 (0x4ad600)
1 | // 伪代码 |
main._a 函数 (0x4ad440) - 核心加密函数
1 | // 伪代码还原 |
MP4文件结构
1 | MP4 File |
攻击原理
stco box 结构
1 | stco box: |
加密过程
1 | 原始: stco -> [1000, 2000, 3000, 4000, ...] |
解密方法
原理
由于加密是简单的加法操作,我们解密只要反向的去把stco的每个chunk的文件偏移量改为减去 0x539 (1337)的值就可以修复了
1 | 加密: stco -> [2337, 3337, 4337, 5337, ...] |
方法一:Python解密脚本
1 | #!/usr/bin/env python3 |
使用方法保存为decrypt_stco.py,然后执行python decrypt_stco.py <input.mp4> [output.mp4] 即可解密成功,可以看到黄金保险柜编号为997546
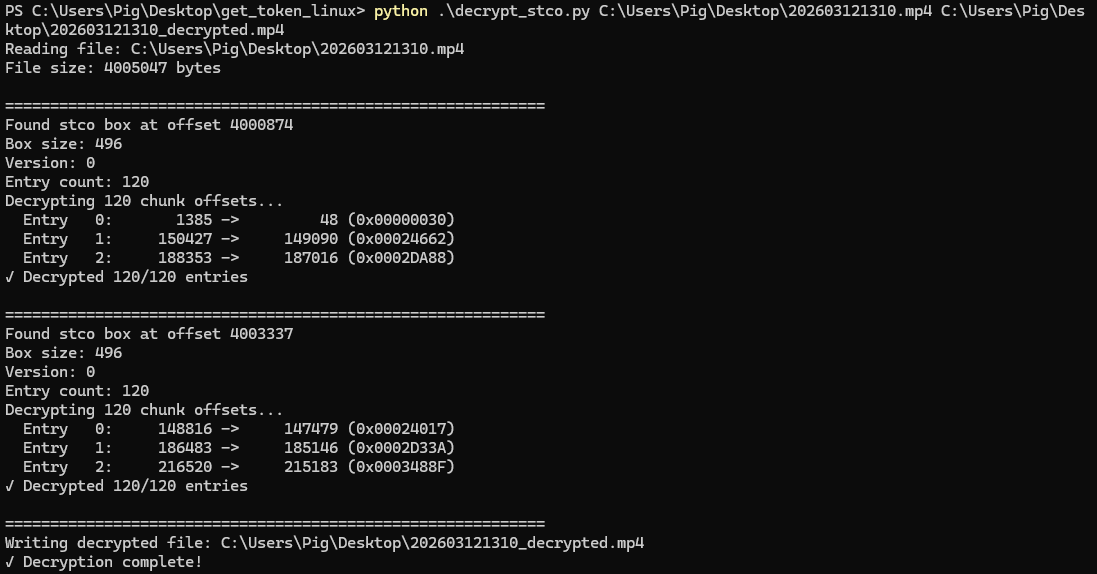

方法二:010 Editor 手动修改
1.1 准备工作
修改文件202603121310.mp4属性,去掉勾选只读,使其可修改
应用MP4.bt模板
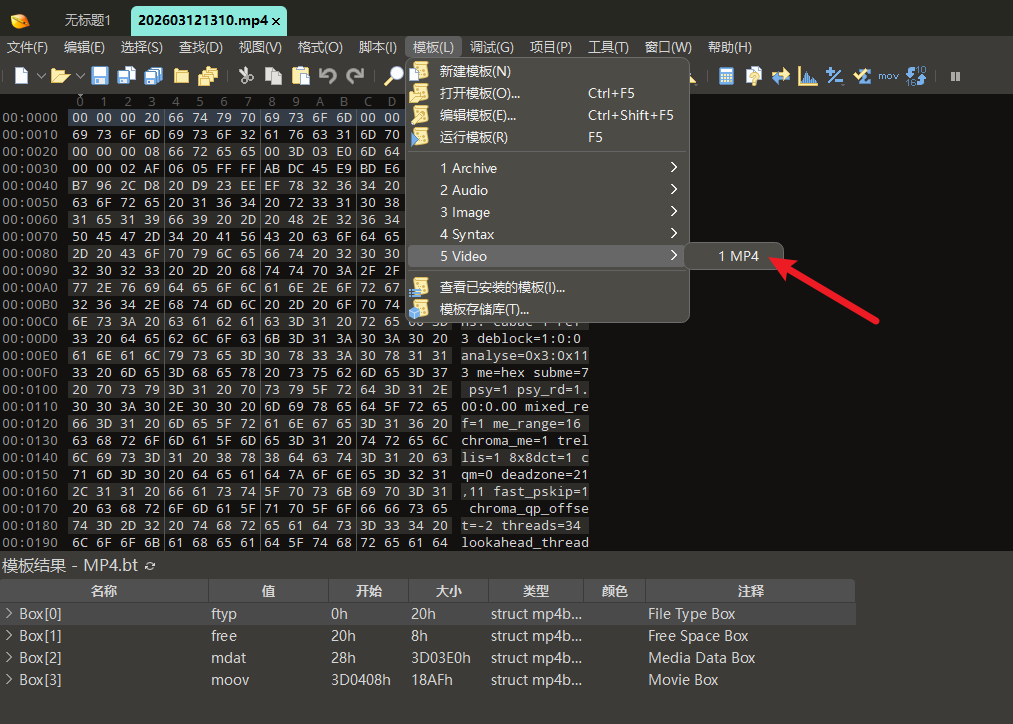
1.2 定位stco box
方法A:文本搜索
1 | 1. 按 Ctrl+F |
方法B:十六进制搜索
1 | 1. 按 Ctrl+F |
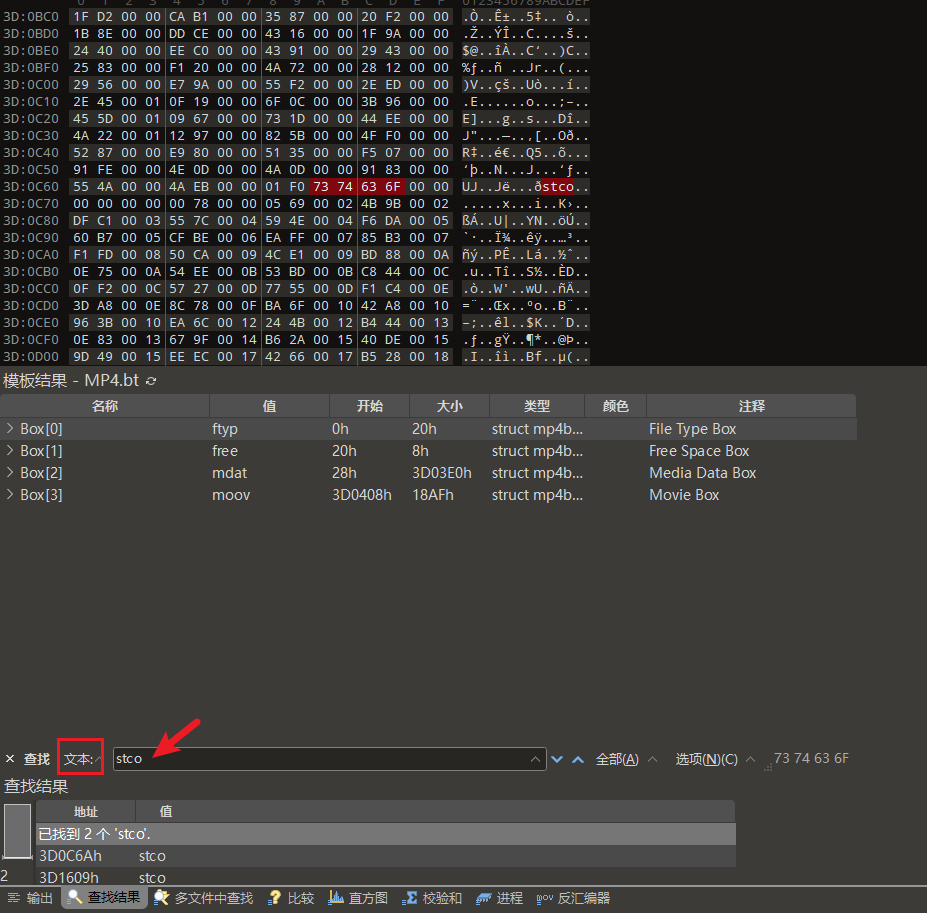
1.3 定位stco box结构
点击第一个搜索结果,然后在十六进制区域高亮的位置点击邮件,选择跳转到模板变量
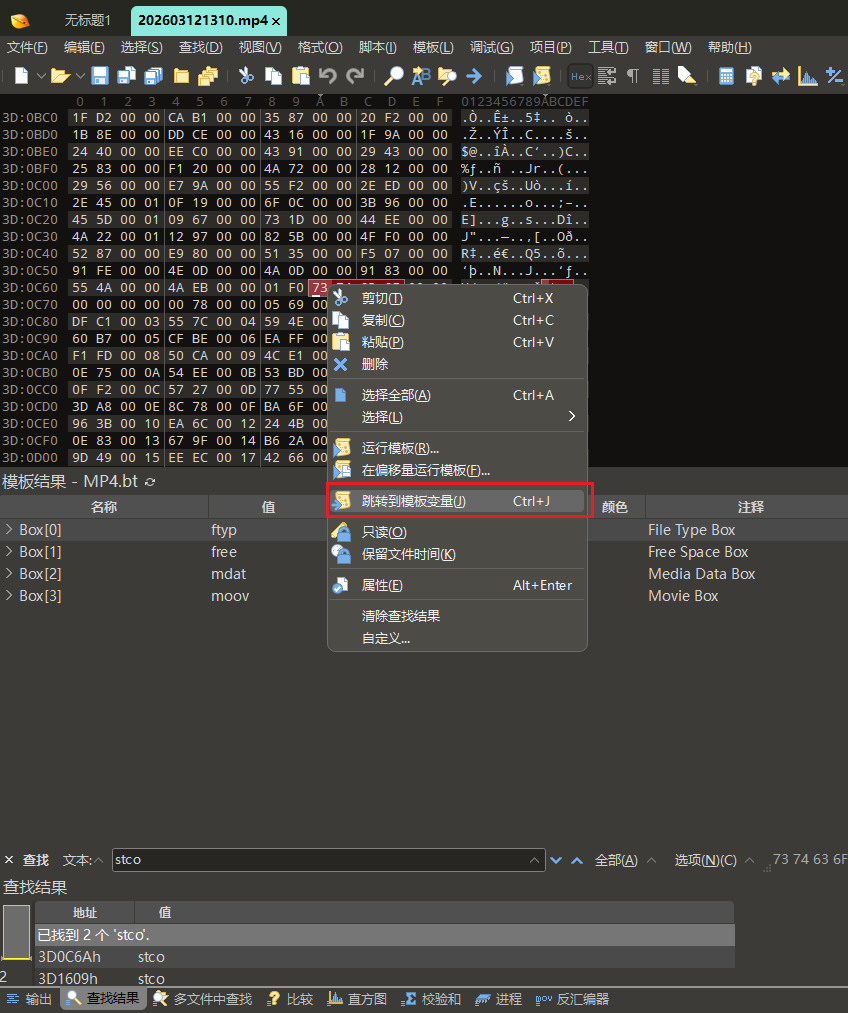
当你找到 stco 后,你看到的数据结构如下:
1 | 位置-4: [00 00 01 F0] ← Box Size (整个stco box的大小) |
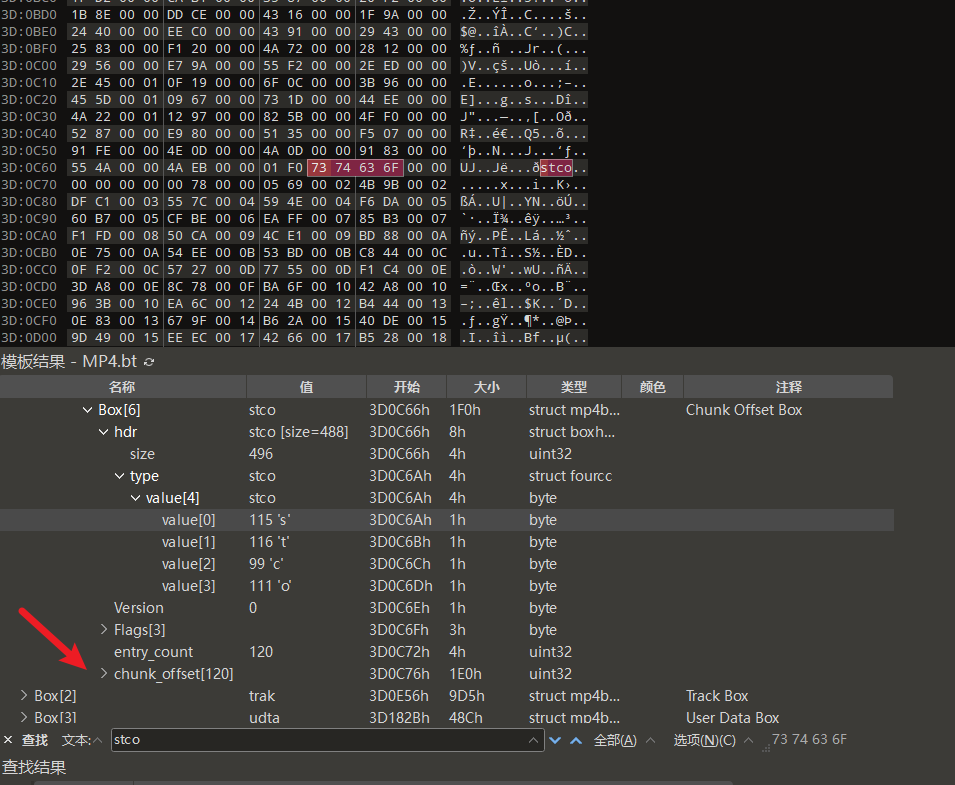
1.4 手动计算并修改
点击展开chunk_offset可以看到若干个chunk_offset,这就是我们需要修改的值
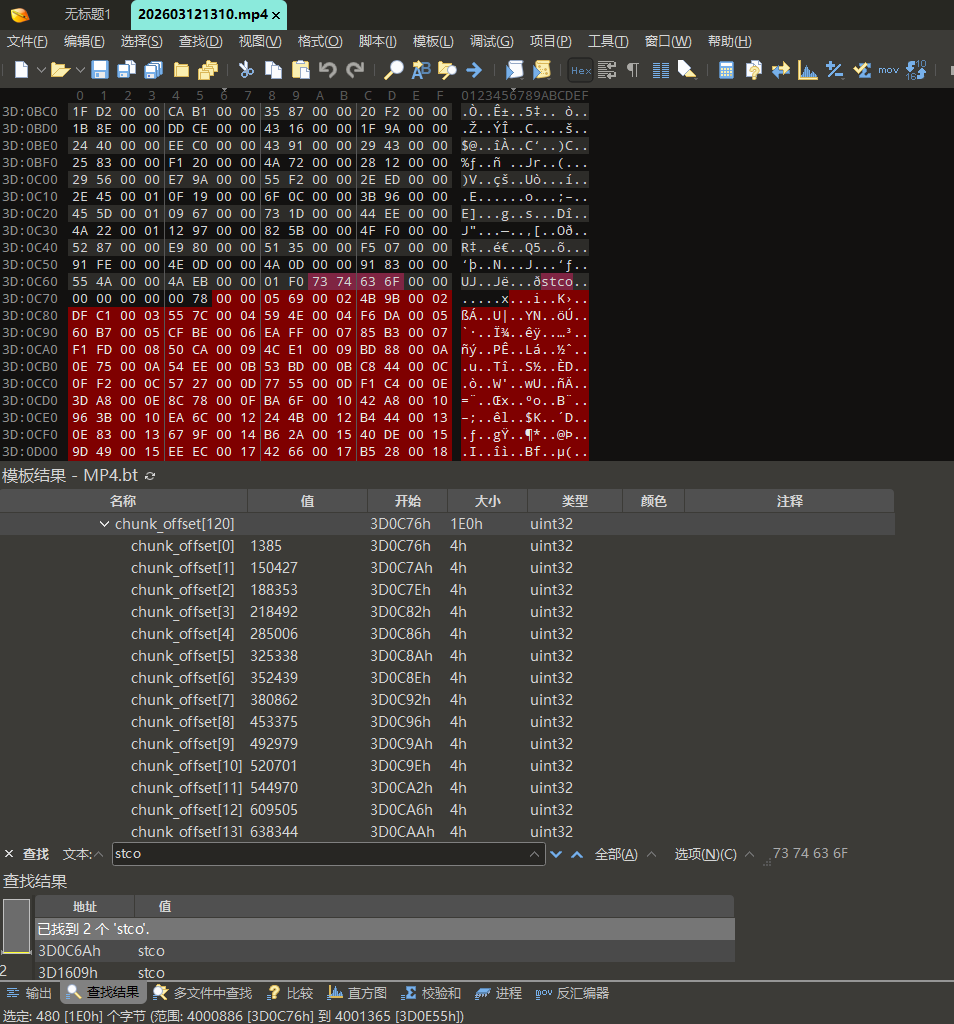
这些chunk offset的值都是恶意程序修改加上0x539 (十进制:1337)后的值,我们还原就需要手动计算这里的值减去1337的结果,并进行修改,如果要完整还原整个视频就需要每个chunk offset都去计算修改,但是在我们这题,只需要修改第一个chunk offset就可以看到第一帧画面得到答案了。
示例:修改第一个chunk offset
计算解密值
1
2chunk_offset[0]的值为1385
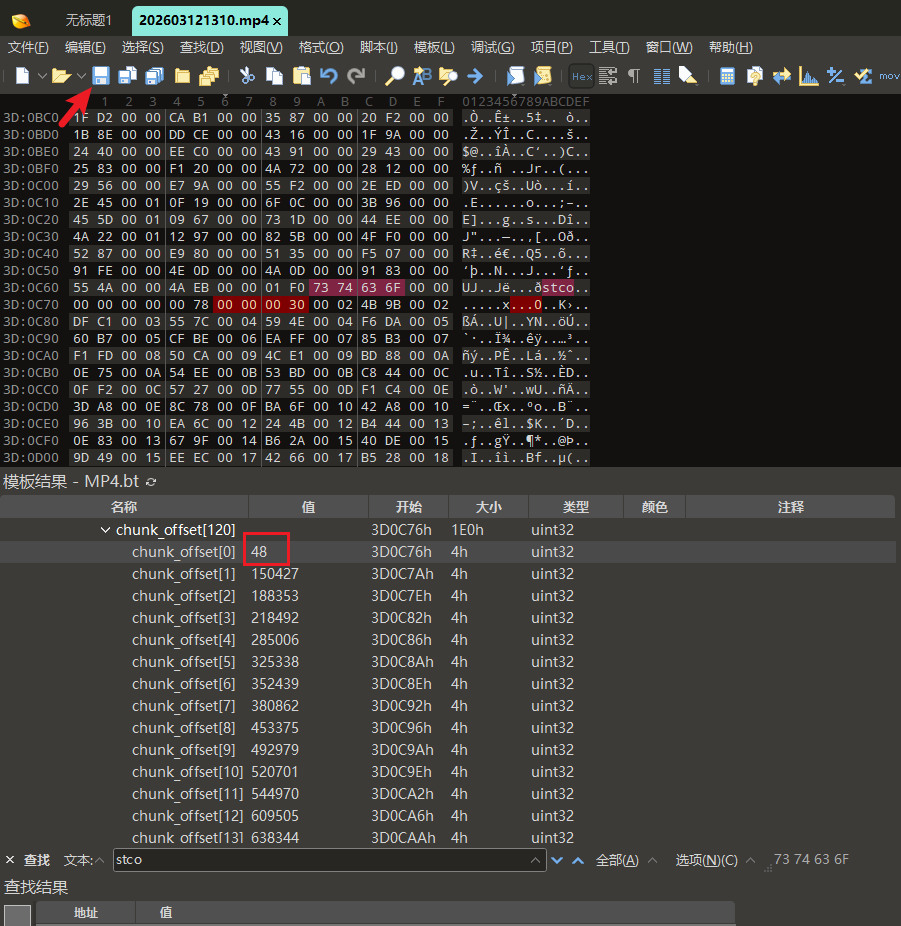
1385 - 1337 = 48修改为解密值
1
将chunk_offset[0]值修改为48
点击保存

10. 分析计算机检材,李安弘电脑中记录的保险柜密码是
13.00 分
【不区分大小写】【不区分空格】【不区分换行符 (不考虑末尾)】【不区分全半角】
【参考格式:123456】
583985
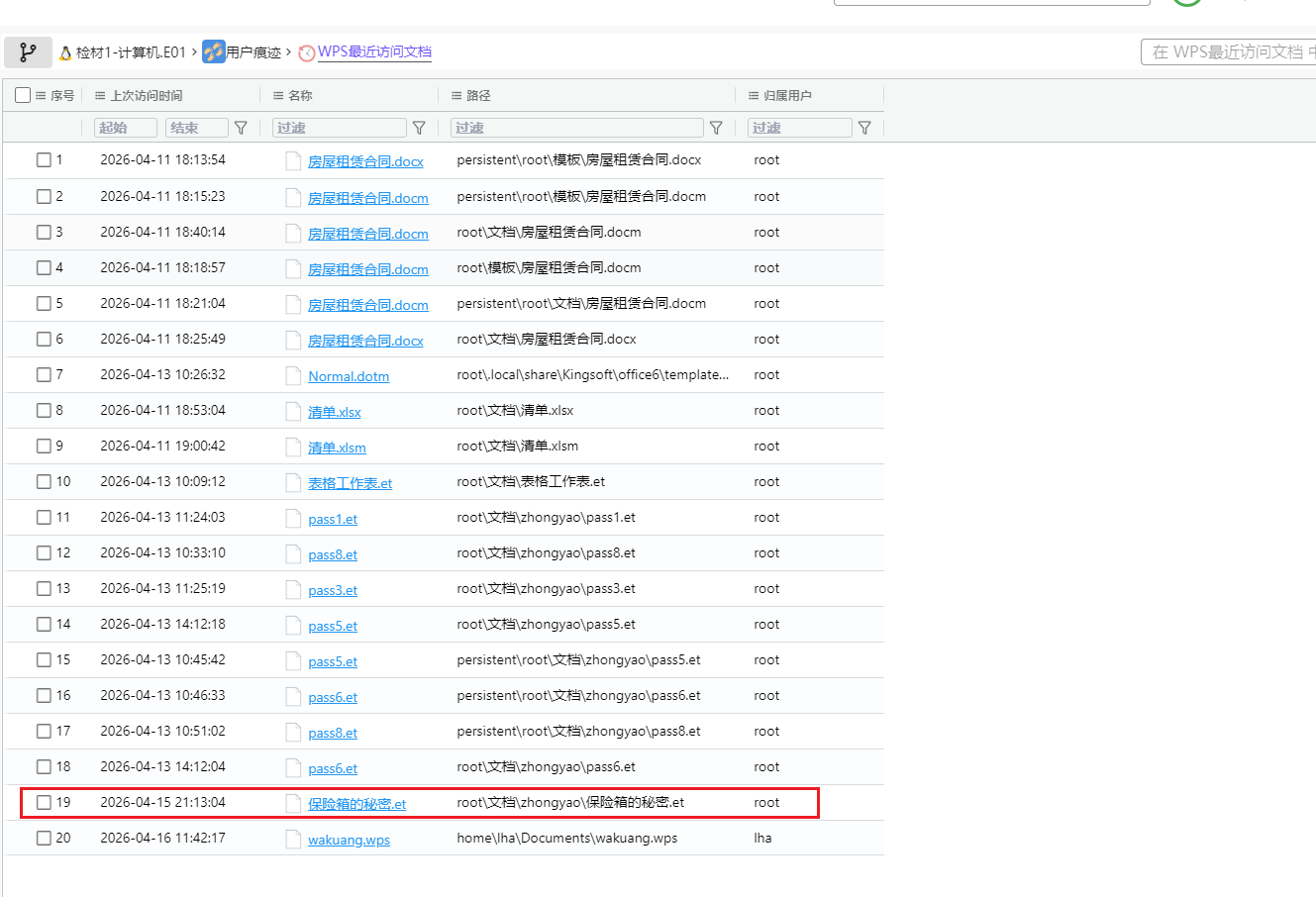
通过查看火眼分析结果:用户痕迹–WPS最近访问文档,可以看到用户访问过一个保险箱的秘密.et的WPS表格文档,打开这个表格文件发现只有点阵图案,没有任何文字信息。通过查看火眼分析结果:firefox浏览器历史记录,可以看到用户曾经搜索查看过”表格加密方法有哪些”、”excel表格怎么加密?”相关内容,这应该是出题人给我们的提示,因此可以初步判定这道题涉及到表格的加密隐写的相关内容
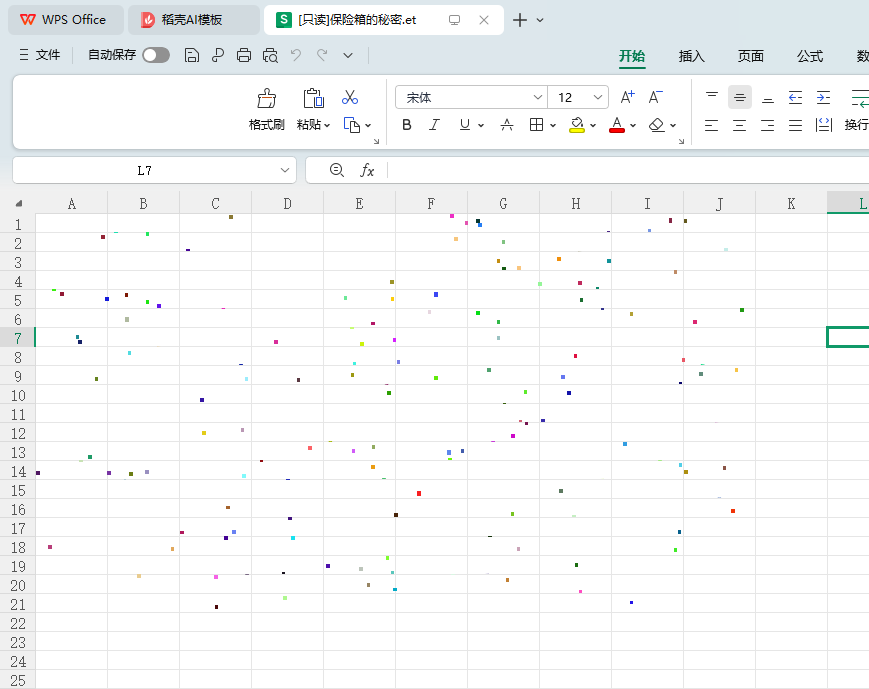
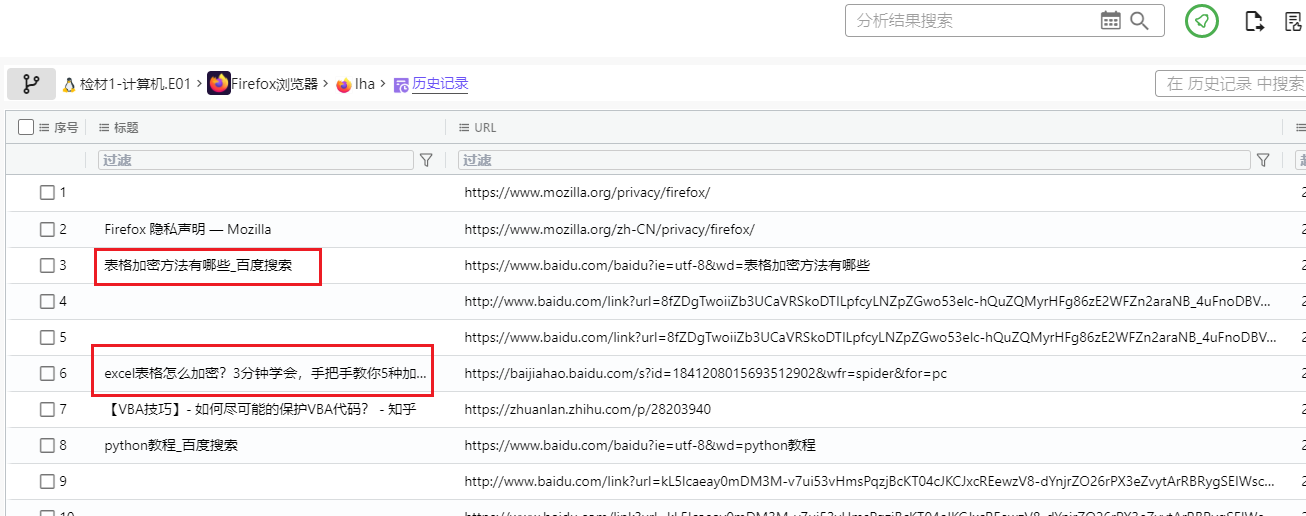
因此我们要寻找到涉及隐写加密的相关文档文件,找到加密方式进而解密。前面我们在做题的过程中发现在用户lha的用户目录下的tool文件夹有大量脚本文件,经过再次仔细查看,发现有一个名为”excelcrypt.txt”,根据文件名也可以判断出这是一个加密excel的脚本。
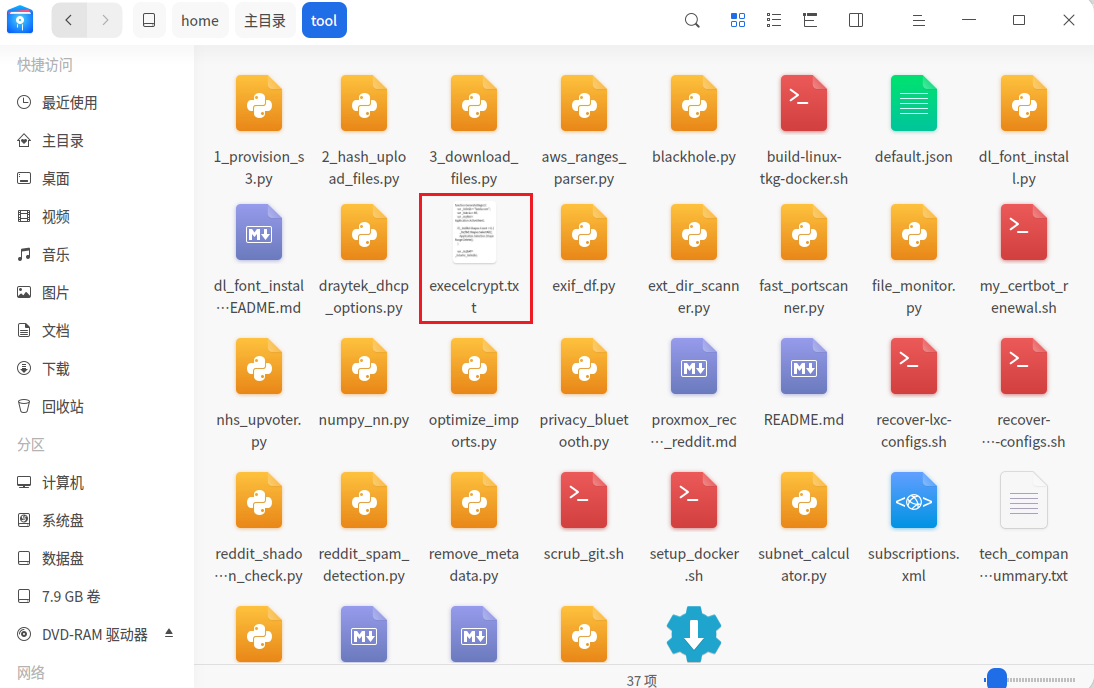
本题又是涉及代码分析和反向解密,具体解题思路如下
一、解题思路概述
通过对 execelcrypt.txt 进行静态分析,还原其点阵隐写算法;再从 .et 文件中定位隐写载体字段 descr,按加密逆过程还原出字符串,即为保险柜密码。
整体流程:
1 | execelcrypt.txt (加密宏) |
二、代码功能识别
首先对 execelcrypt.txt 进行了静态分析。该文件是一段经过混淆的 WPS/Excel JavaScript 宏代码,核心功能为点阵隐写生成器。
代码将目标字符串转换为自定义点阵字体定义的像素坐标,再通过创建大量微小矩形形状(3×3 像素)将加密后的坐标数据写入每个形状的 AlternativeText 属性中。
2.1 字符串拆分为字符
代码把 "baidu.com" 逐个字符拆开,先处理第一个字符 'b'。
2.2 字符映射为点阵坐标
代码中有一张字模表 _0xfont,它定义了每个字符由哪些像素点组成。例如字符 'b' 的定义是:
1 | 'b': [[0,0],[0,1],[0,2],[1,2],[2,2],[0,3],[3,3],[0,4],[1,4],[2,4]] |
这表示 'b' 由 10 个像素点构成。每个中括号里的两个数字是相对坐标 (mx, my),含义为”相对于该字符左上角的偏移”。
2.3 相对坐标 → 绝对坐标
这些点不能直接使用,需要放置到整张表格的画布上。换算规则为:
- 每个字符占 25 像素宽,第
i个字符的基线横坐标为i × 25 - 相对坐标要乘以缩放因子 4
以字符 'b'(第 0 个字符,i = 0)为例:
| 相对坐标 | 计算过程 | 绝对坐标 |
|---|---|---|
[0,0] |
x = 0×25 + 0×4 = 0;y = 0×4 = 0 |
(0, 0) |
[0,1] |
x = 0×25 + 0×4 = 0;y = 1×4 = 4 |
(0, 4) |
[0,2] |
x = 0×25 + 0×4 = 0;y = 2×4 = 8 |
(0, 8) |
2.4 绝对坐标加密为整数
代码把每个绝对坐标 (x, y) 加密成一个整数 N,加密过程为:
1 | a = (x + 100) XOR 85 |
以第一个点 (0, 0) 为例:
1 | a = (0 + 100) XOR 85 = 100 XOR 85 = 49 |
2.5 数字写入形状 AlternativeText
代码创建一个 3×3 像素的微小矩形形状,然后把 N = 49049 写入该形状的 AlternativeText 属性:
1 | var _0x99aa = _0x2f8d.Shapes.AddShape(1, _0x7788, _0x8899, 3, 3); |
关键代码段(去混淆后)如下:
1 | var _0x5e2b = "baidu.com"; // 示例隐写内容 |
2.6 AlternativeText → descr 映射
在 Office 对象模型中,AlternativeText 在 OOXML 序列化时会映射为 <xdr:cNvPr> 元素的 descr 属性。当文件保存为 .et 格式时,WPS 会把 AlternativeText 的值写入 XML 文件的 descr 字段。
2.7 还原思路
综上所述,要还原密码,必须完成以下步骤:
- 找到存有
descr字段的 XML 文件 - 从 XML 中提取所有
descr字段(其值即加密后的整数N) - 按形状
id顺序排列所有descr - 把
N拆成a和b,异或85、减100,还原出绝对坐标(x, y) - 根据坐标逆推每个字符在字模表中的位置,还原原始字符串
解密公式:
$$
\begin{aligned}
a &= \left\lfloor \dfrac{N}{1000} \right\rfloor \[4pt]
b &= N \bmod 1000 \[4pt]
x &= (a \oplus 85) - 100 \[4pt]
y &= (b \oplus 85) - 100
\end{aligned}
$$
三、查找 descr 属性所在文件位置
3.1 文件格式识别
通过查看 保险箱的秘密.et 的文件头:
1 | D0 CF 11 E0 |
确认该文件为 OLE 复合文档(Compound File Binary Format),这是早期 Microsoft Office 及 WPS 兼容格式所采用的标准封装结构。
3.2 OLE 流结构解析
使用 7zip 打开 保险箱的秘密.et,可发现其内部有四个流:
| 文件名 | 大小 | 分析结论 |
|---|---|---|
[5]DocumentSummaryInformation |
456 B | 文档摘要信息 |
[5]SummaryInformation |
220 B | 摘要信息 |
ETExtData |
594 B | WPS 扩展数据流 |
Workbook |
413,705 B | 核心工作表数据,重点分析对象 |
Workbook 流占据绝大部分文件体积,是隐写数据的首要排查目标。
3.3 嵌入 ZIP 数据包的发现
使用 binwalk 扫描 Workbook:
1 | binwalk Workbook |
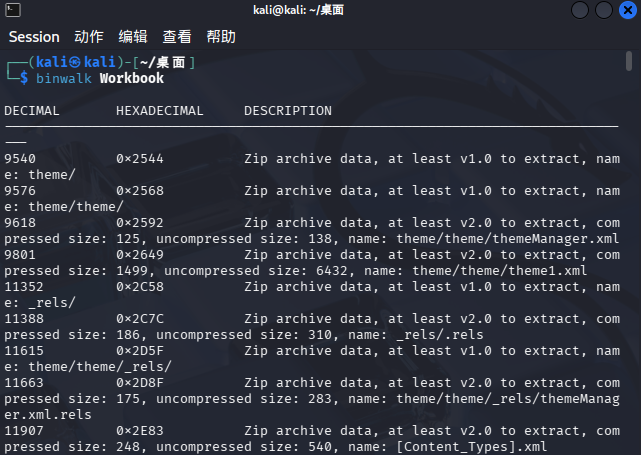
可以看到该文件内嵌了大量压缩包。使用下列命令批量提取:
1 | binwalk -e Workbook |
共提取出 172 个压缩包,再使用 Bandizip 批量解压。
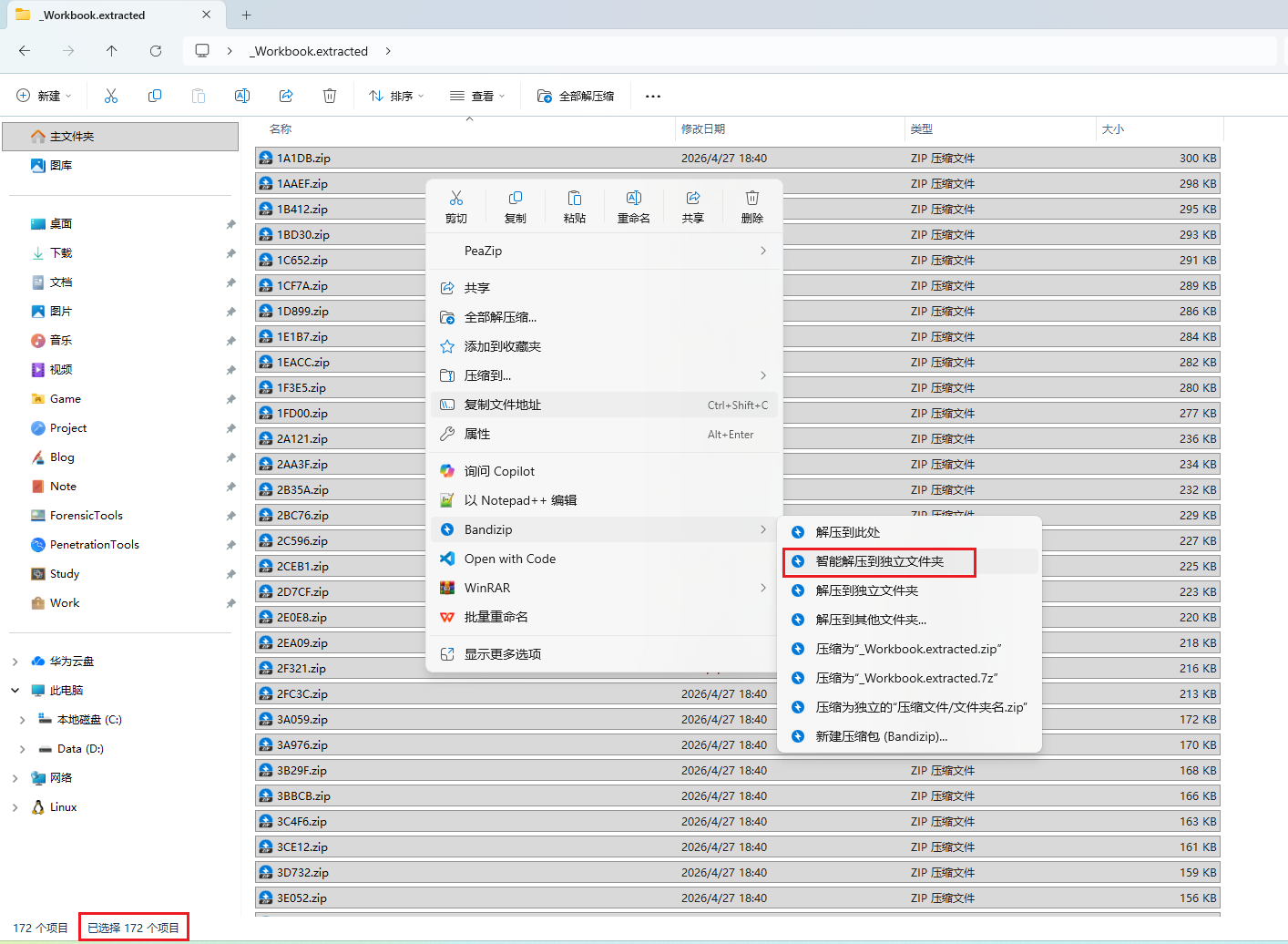
3.4 形状 XML 结构与关键字段定位
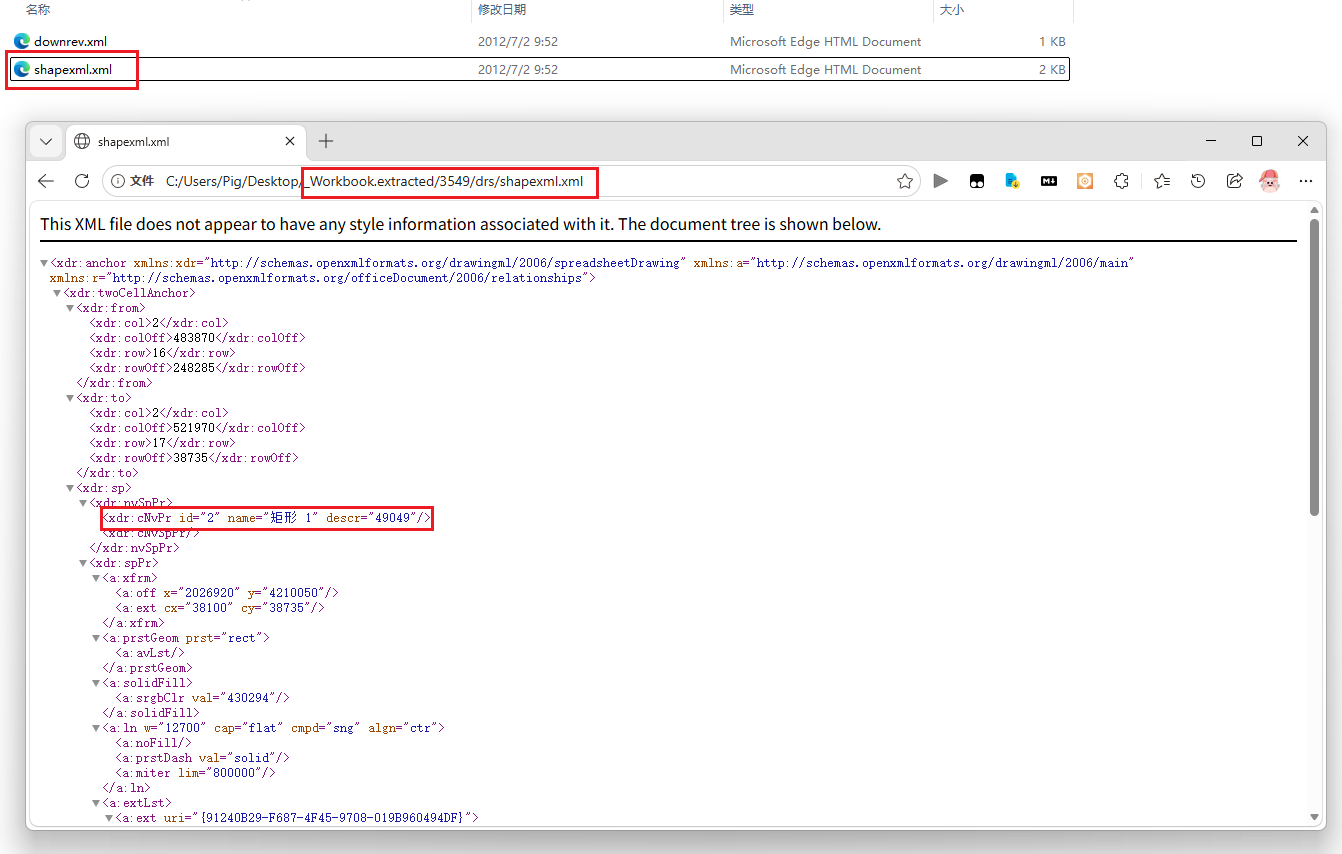
解压后,每个压缩包内都有一个 drs/shapexml.xml 文件。通过全文检索 descr,可快速定位到关键节点:
1 | <xdr:cNvPr id="2" name="矩形 1" descr="49049"/> |
这里 descr 的值就是坐标信息被加密后的整数 N,也是我们需要逆向还原的对象。
四、数据提取与解密思路
4.1 提取密文
提取每个 shapexml.xml 中的 descr 值,并按形状 id 升序排序。前 10 条提取结果如下:
| ID | descr(密文 N) |
|---|---|
| 2 | 49049 |
| 3 | 49061 |
| 4 | 49057 |
| 5 | 61057 |
| 6 | 57057 |
| 7 | 49037 |
| 8 | 37037 |
| 9 | 49033 |
| 10 | 61033 |
| 11 | 57033 |
4.2 坐标解密
对每条密文应用解密公式,以 ID=2, N=49049 为例:
$$
\begin{aligned}
a &= \left\lfloor \dfrac{49049}{1000} \right\rfloor = 49 \[4pt]
b &= 49049 \bmod 1000 = 49 \[4pt]
x &= (49 \oplus 85) - 100 = 100 - 100 = 0 \[4pt]
y &= (49 \oplus 85) - 100 = 100 - 100 = 0
\end{aligned}
$$
得到坐标 (0, 0)。对全部 171 个密文执行相同运算,得到完整的坐标点集。
4.3 字符还原
根据坐标生成公式的逆运算,将绝对坐标转换为字符索引和相对点阵坐标:
$$
\begin{aligned}
i &= \left\lfloor \dfrac{x}{25} \right\rfloor \[4pt]
mx &= \left\lfloor \dfrac{x \bmod 25}{4} \right\rfloor \[4pt]
my &= \left\lfloor \dfrac{y}{4} \right\rfloor
\end{aligned}
$$
按字符索引 i分组,每组即得一个相对点阵坐标集合。将其与 _0xfont 字模表比对,找到完全匹配的字符。
以字符索引 i = 0为例,其相对点阵坐标集合为:
$$
{(0,0),\ (0,1),\ (0,2),\ (0,3),\ (0,4),\ (1,2),\ (1,4),\ (2,2),\ (2,4),\ (3,3)}
$$
与字模表比对,该坐标集合与字符 'b' 的定义完全一致。
依次执行比对,得到完整字符序列:
1 | b a o x i a n g u i m i m a : 5 8 3 9 8 5 |
即字符串 **baoxianguimima:583985**。
其中 baoxianguimima 为”保险柜密码”的拼音,冒号后的数字即为保险柜密码。
五、解密方法实现
方法一:Python 自动化脚本
以下为本次分析中使用的 Python 解密脚本,供同行参考:
1 | #!/usr/bin/env python3 |
方法二:EmEditor + Excel 手动解密
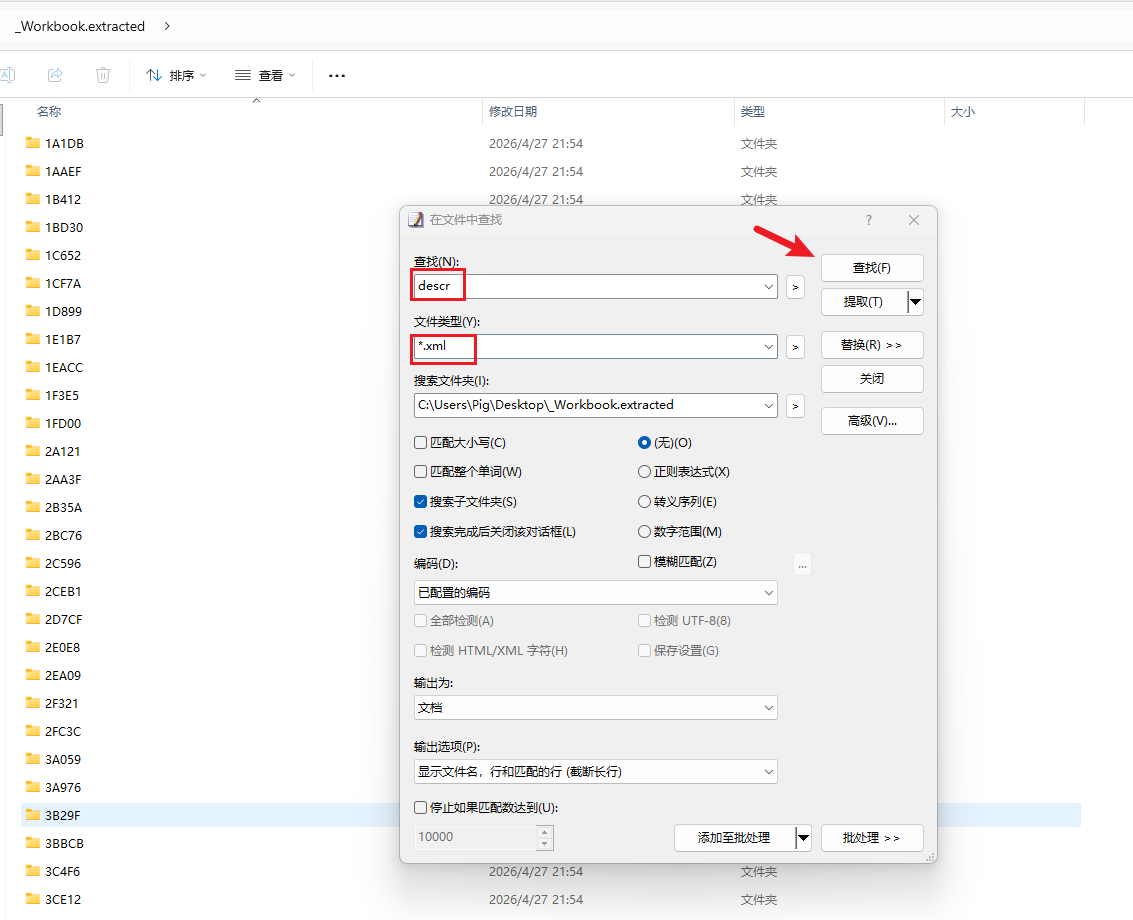
5.2.1 使用 EmEditor 提取 descr 行
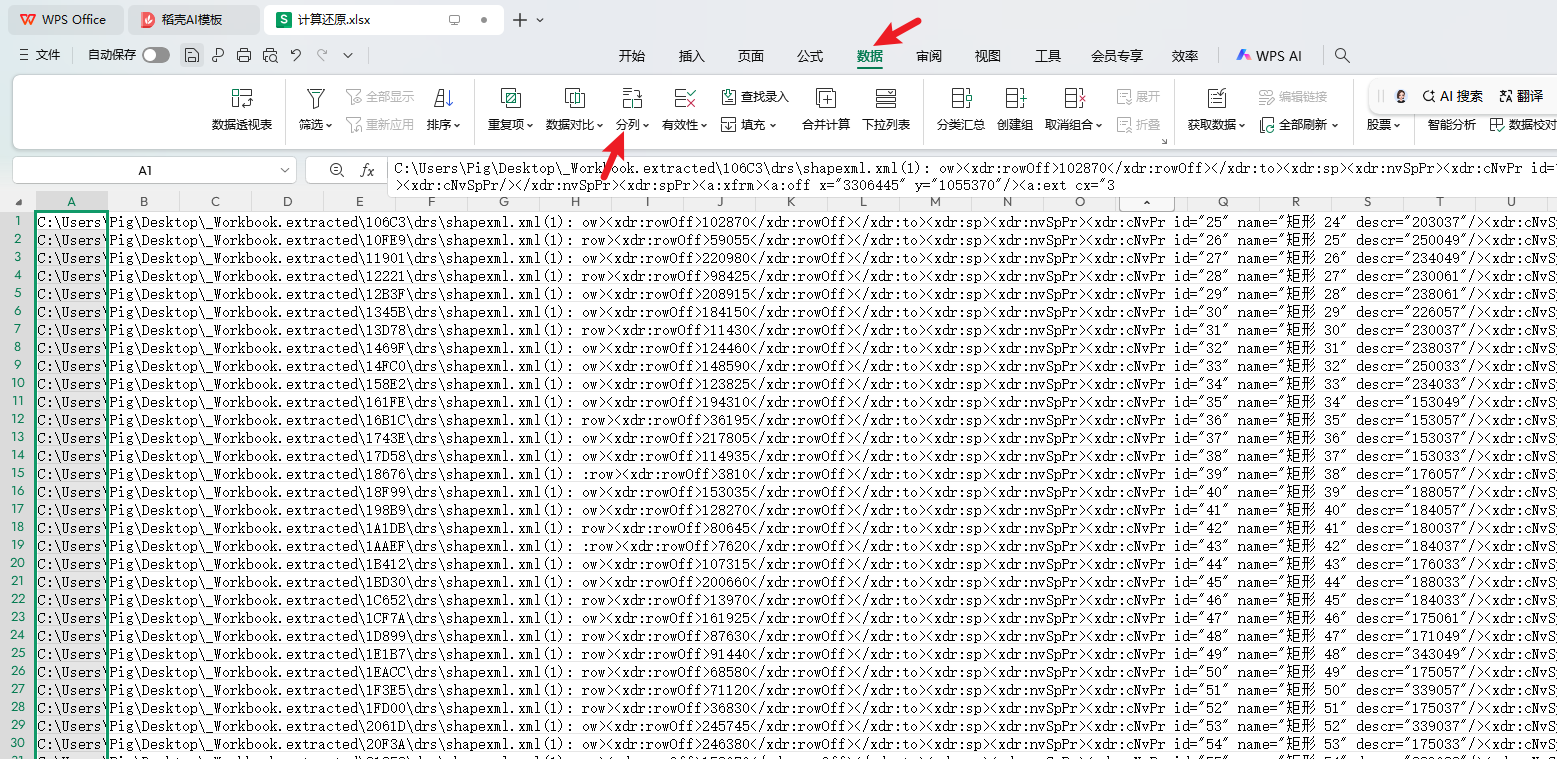
使用 EmEditor 的”在文件中查找”功能,对解压后得到的全部 shapexml.xml 进行全量搜索关键字 descr,即可一次性提取出所有包含 descr 的行,共有171行
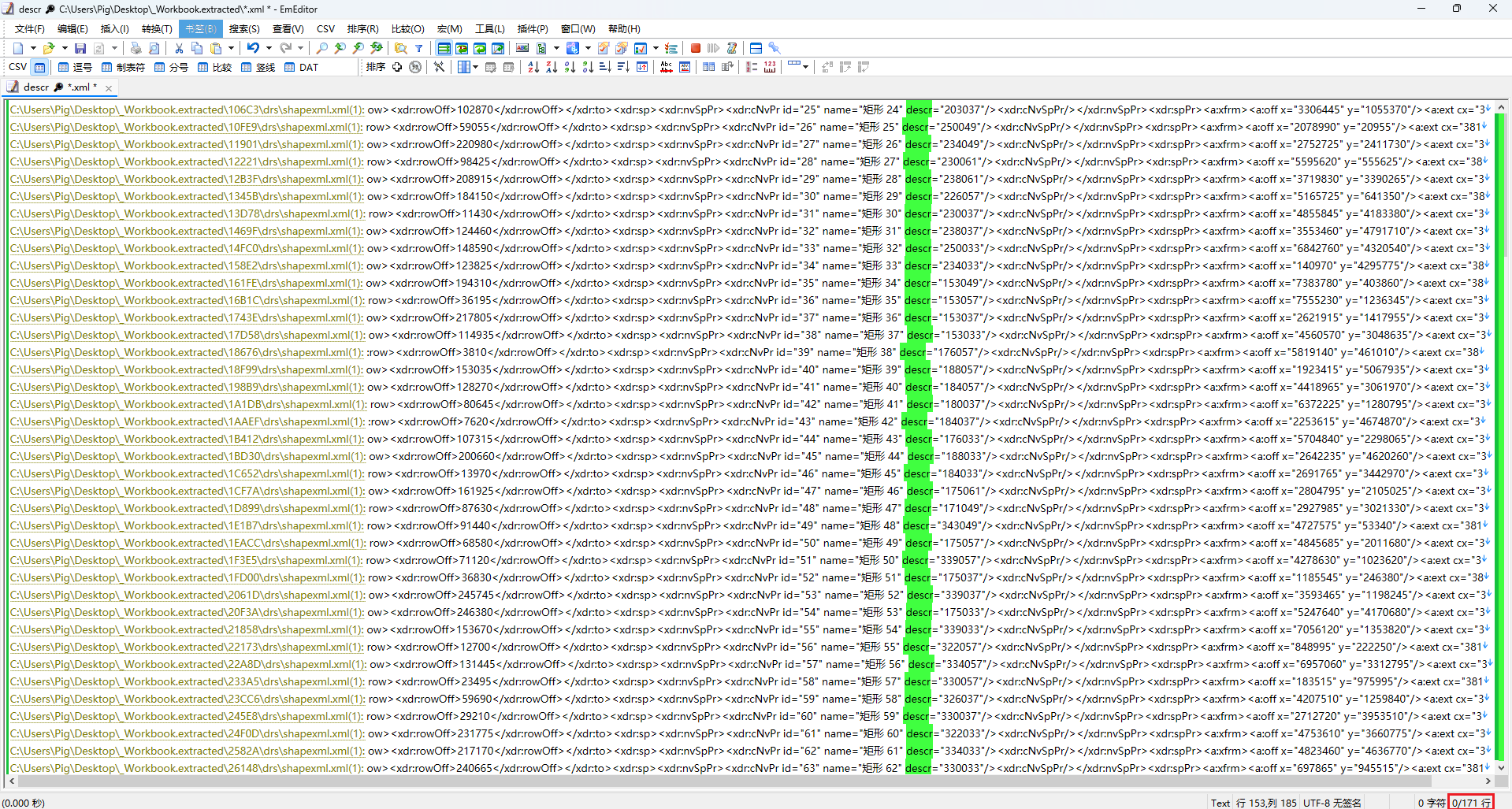
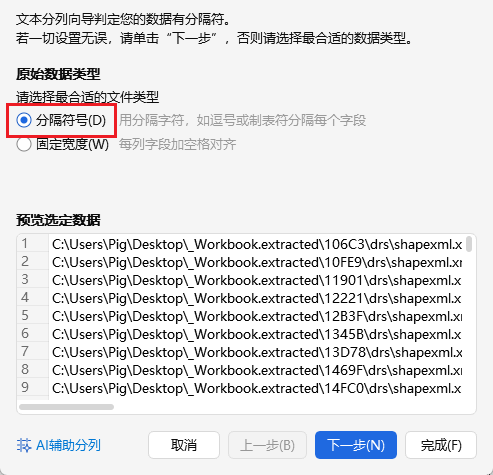
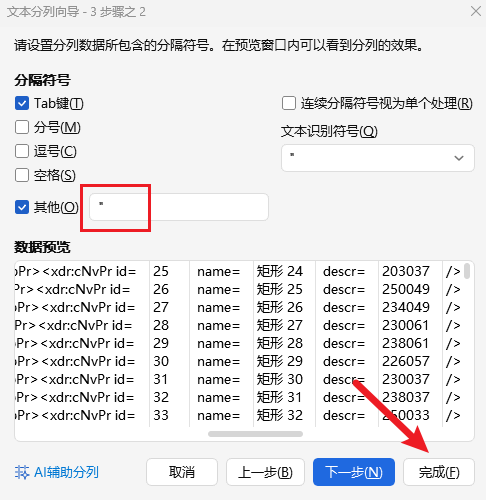
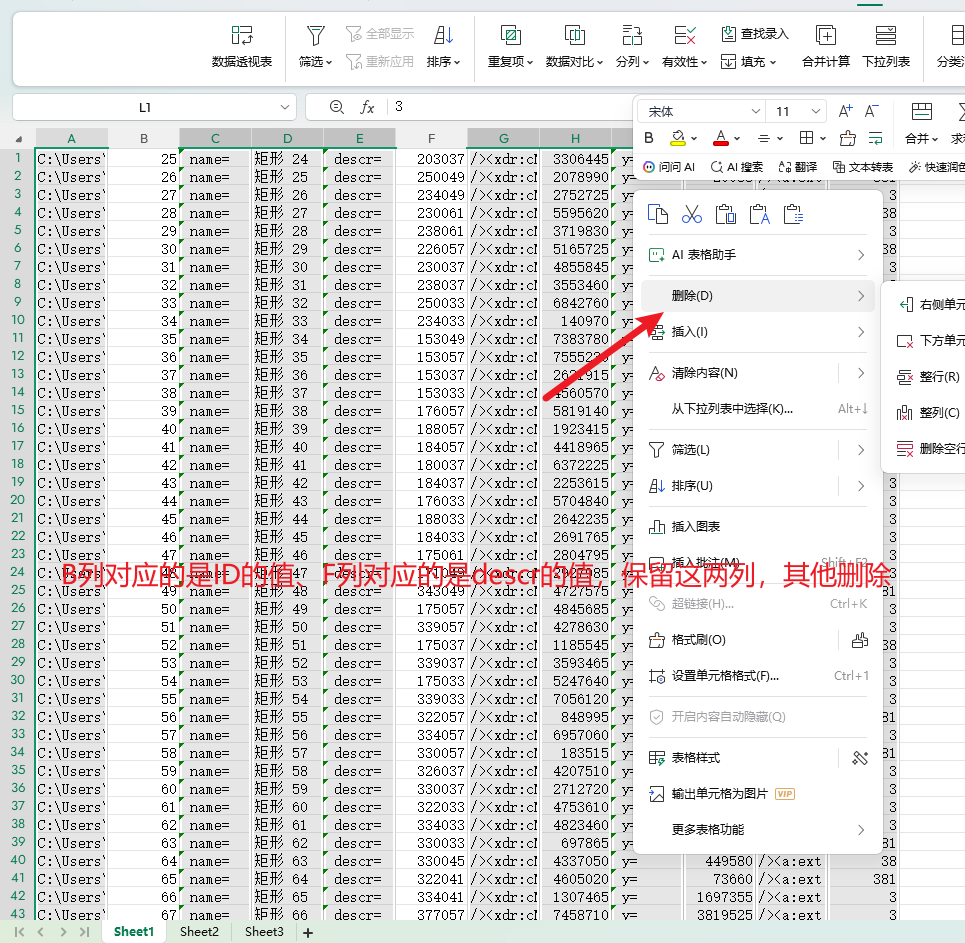
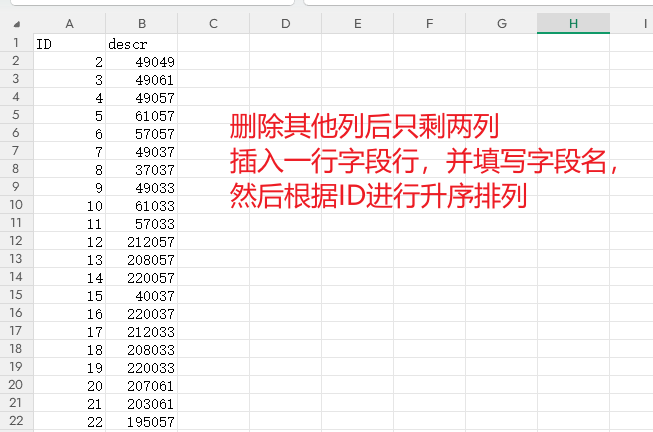
5.2.2 使用 Excel 分列提取 ID 与 descr
将提取到的结果复制粘贴到 Excel 中,使用分列功能,以英文双引号 " 作为分隔符,把 id 的值与 descr 的值提取到独立列,删除其他无关列:
- A 列:
id - B 列:
descr(密文 N)
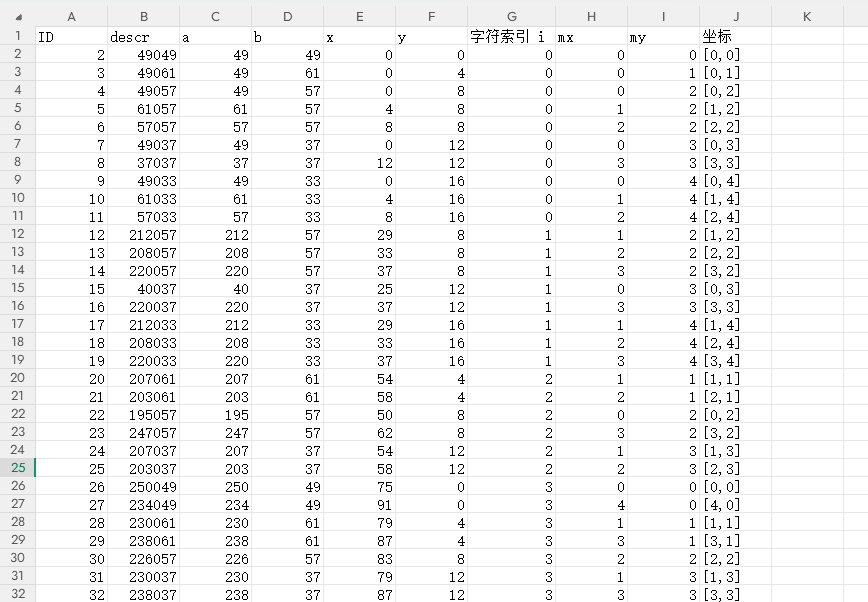
在 C2 ~ J2 分别输入以下公式,然后向下填充至第 172 行:
| 列 | 标题 | 公式 |
|---|---|---|
| C | a | =INT(B2/1000) |
| D | b | =MOD(B2,1000) |
| E | x | =BITXOR(C2,85)-100 |
| F | y | =BITXOR(D2,85)-100 |
| G | 字符索引 i | =INT(E2/25) |
| H | mx | =INT(MOD(E2,25)/4) |
| I | my | =INT(F2/4) |
| J | 坐标 | ="["&H2&","&I2&"]" |
⚠️
BITXOR是 Excel 2013 及以上版本提供的函数。若 Excel 版本过旧,请使用 Windows 计算器手工计算异或。
输入公式后,拖动填充柄即可批量计算出所有行的值。

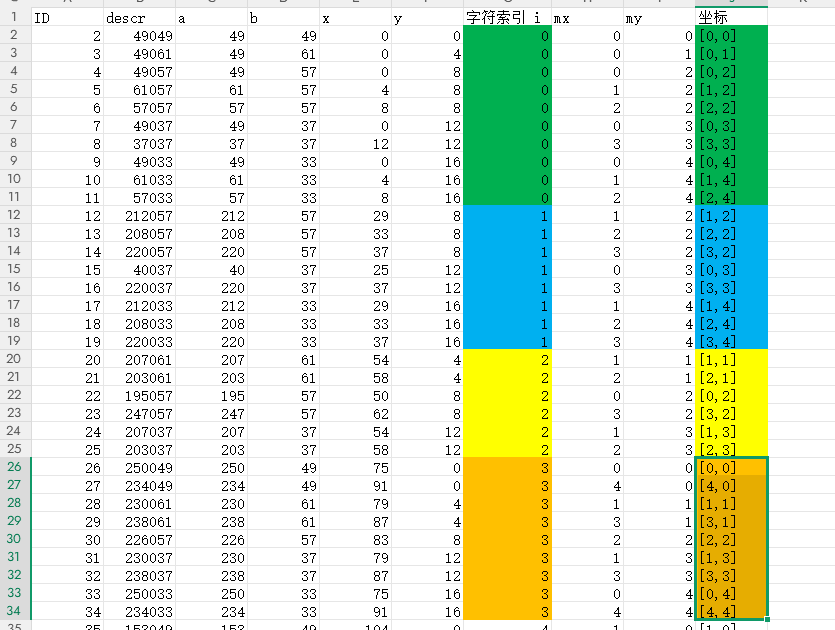
5.2.3 按字符索引分组
将字符索引 i 相同的 (mx, my) 归为一组,得到如下形式的分组:
1 | 字符索引 0 : [[1,0],[2,0],[0,1],[3,1],[0,2],[3,2],[0,3],[3,3],[1,4],[2,4]] |
5.2.4 手工比对字模表
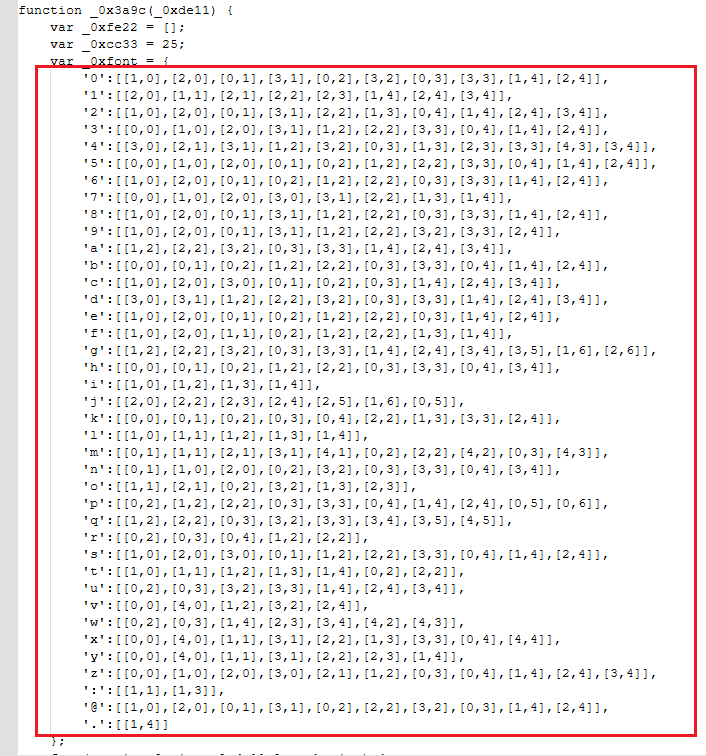
把每一组的 (mx, my) 点集与 execelcrypt.txt 中的字模表进行比对。
以字符索引 0 为例:
点集为 (0,0),(0,1),(0,2),(0,3),(0,4),(1,2),(1,4),(2,2),(2,4),(3,3)
在字模表中逐项比对:
'a'是 8 个点 → 不匹配'b'是[[0,0],[0,1],[0,2],[1,2],[2,2],[0,3],[3,3],[0,4],[1,4],[2,4]]→ 完全匹配
故第 0 个字符为 **b**。
以字符索引 1 为例:
点集为 (0,3),(1,2),(1,4),(2,2),(2,4),(3,2),(3,3),(3,4)
与 'a' 的定义 [[1,2],[2,2],[3,2],[0,3],[3,3],[1,4],[2,4],[3,4]] 完全匹配,故第 1 个字符为 **a**。
依次类推,可得如下对应关系:
| 索引 | 字符 | 索引 | 字符 | 索引 | 字符 |
|---|---|---|---|---|---|
| 0 | b | 7 | g | 14 | : |
| 1 | a | 8 | u | 15 | 5 |
| 2 | o | 9 | i | 16 | 8 |
| 3 | x | 10 | m | 17 | 3 |
| 4 | i | 11 | i | 18 | 9 |
| 5 | a | 12 | m | 19 | 8 |
| 6 | n | 13 | a | 20 | 5 |
即字符串 **baoxianguimima:583985**。
六、最终结果
| 项目 | 内容 |
|---|---|
| 还原字符串 | baoxianguimima:583985 |
| 语义解读 | baoxianguimima = “保险柜密码”的拼音 |
| 保险柜密码 | 583985 |



.png)




